
美团 2面:G1 为什么能替代 CMS收集器?看完这篇就懂了!
你好,我是猿java
在 《肝了一周,彻底弄懂了 CMS收集器原理,这个轮子造的真值! 》这篇文章中,
详细地分析了 CMS收集器,刚好这两天看了一道美团 2面的题目:G1 为什么能替代 CMS收集器?借此机会,把 G1收集器以及它和 CMS的对比一并彻底讲解。
写在前面
由于 JDK版本的快速迭代,笔者在写这篇文章时,JDK最后的 release版本是:JDK 22(2024年3月19日正式发布)。
另外,在整理 Oracle官方关于 JVM垃圾收集器的资料时,发现有主流的 3种版本,整理如下:
1.Oracle官方教程
这个网站是 Oracle技术网络教程,内容可能更侧重于实际应用、示例、性能调优和最佳实践。 比如 G1收集器:https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html ,
HotSpot VM 内存管理白皮书:https://www.oracle.com/technetwork/java/javase/memorymanagement-whitepaper-150215.pdf
这个网站提供官方的、详细的技术文档,包括用户手册、参考指南、白皮书和发行说明,更权威和细节化。比如:https://docs.oracle.com/en/java/javase 是关于 JDK各版本的介绍。
- YouTuBe 官方的一些频道
比如:Java
2.JVM 开发者 Oracle工程师的博客
比如:https://tschatzl.github.io ,这个网站是 HotSpot虚拟机深度开发者,Oracle工程师 Thomas Schatzl的个人博客,Schatzl于2009年参与 JVM开发至今,目前是 G1收集器的 Leader engineer。
3.Sun公司早期的一些技术论文
Java早期是 Sun公司的产品,2009年4月20日 Sun被 Oracle收购,因此,早期的一些学术论文还是比较有参考价值,比如:
吞吐量屏障在 G1收集器中的探索:https://ssw.jku.at/Teaching/MasterTheses/Protopopovs/Thesis.pdf ,
Sun 公司 G1 学术论文: http://cs.williams.edu/~dbarowy/cs334s18/assets/p37-detlefs.pdf
尽管每个 JDK版本对 G1的描述略有差异,但是其核心思想是一样的,关于各个版本中 G1的改动点,可以找到本文末尾对应的章节。
另外,为了更好的理解本文,建议先阅读文章开头关于CMS收集器的文章,里面对三色标记法,记忆集,卡表等技术做了比较详细的介绍。
G1 简介
G1 最初起源于 2004年的 Sun公司 G1学术论文 ,在 2012年9月 JDK 7 Update 4 正式投入商业使用,耗时 8年之久,这么长的时间,应该能想象其实现难度。
G1 是 Garbage First 的简称,可以翻译成“垃圾优先”,它是一款面向服务器的垃圾收集器,采用标记整理算法,用于大内存的多处理器计算机,目标是实现低延时垃圾回收,从 2017年9月发布的 JDK9 开始,G1 就已经成为了默认的垃圾收集器。
Oracle官方给 G1的定位是用来替代 CMS收集器,这就是为什么很多文章会把 G1 和 CMS进行对比的根本原因。
事实证明 G1确实不辱使命,我们暂且不谈它的回收性能如何,至少它为以后那些优秀的垃圾收集器奠定了 3个坚实的基础:
- 基于 Region 的内存布局
- 面向局部收集的设计思想
- GC停顿时间和吞吐量的平衡
可以说,G1 的诞生,除了 Oracle公司的巨大付出之外,硬件的快速发展以及成本的降低也是决定它成败的一个关键因素。
G1 堆内存结构
和以往的垃圾收集器不一样,G1尽管依然保留了年轻代(young generation)和老年代(old generation)的概念,
但是它们已经变成了一个逻辑上的概念,G1的堆内存被切分成若干个大小(1M ~ 32M)相同且不连续的 Region,包括 Eden,Survivor,Old Generation, Humongous,
具体的堆内存结构如下图:
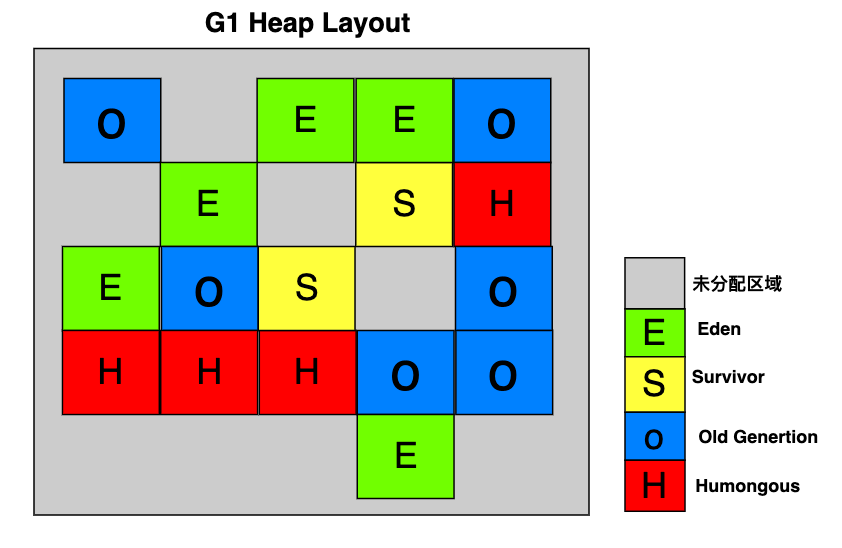
Eden 区(绿色带“E”)和 Survivor区(黄色带“S”)的组合就是通常说的年轻代。
Humongous(红色带“H”)是 G1 提出来的一个新区域,专门用于存储大对象,这里的大对象是指内存占用大于等于单个 Region一半大小的对象。
比如,假设每个 Region是 2M,如果当前对象是 1M,那么它就是一个大对象,如果当前对象的大小是 3M,超过 1个 Region的范围,
那么 G1会寻找连续的 2个 Humongous Region来存放它,如果找不到连续的空间存放当前对象,
G1可能会触发一次垃圾回收来释放空间,或者进行内存压缩操作。
对于 Region,可以通过 -XX:G1HeapRegionSize参数设置其大小,比如:-XX:G1HeapRegionSize=4M,代表每个 Region的大小是 4M。
从 JVM运行时内存结构的角度看,G1 回收对象是整个堆内存,如下图:
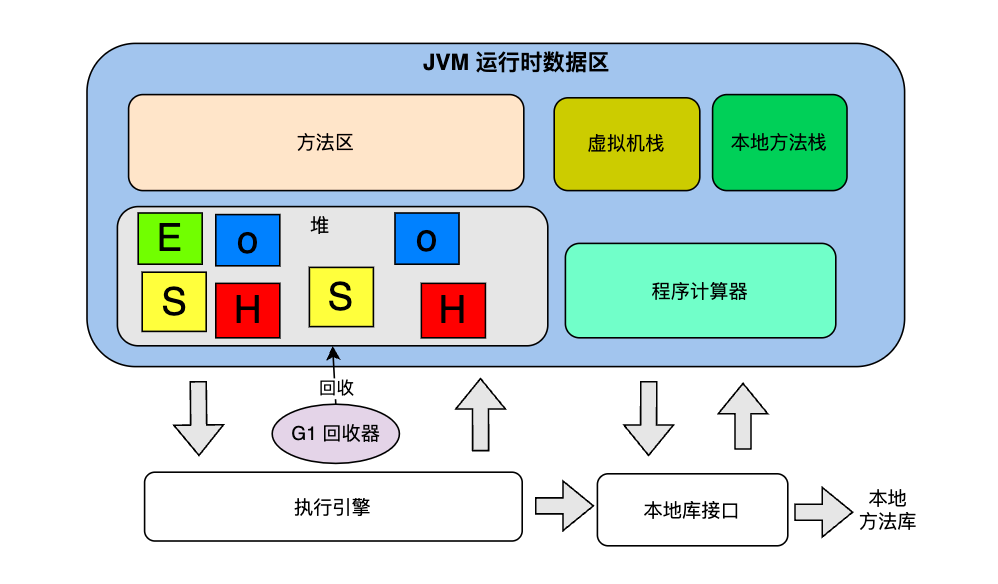
Region的特别说明:一个 Region可以是 Eden,Survivor,Old,Humongous 4种角色中的任意一种。在垃圾回收的过程中,存活对象可以从一个 Region 移动到另一个 Region,
比如,从 Eden区 移动到 Survivor区,从 Survivor区移动到老年代,所以,每个 Region具体属于哪一种角色也是动态变化的。理解这一点,可以帮助我们更好地领会下文 G1的回收原理。
几个重要技术点
在 CMS收集器这篇文章中,我们分析过三色标记法,记忆集,卡表,可达性分析等重要技术,作为 CMS的替换者和继承人,G1也使用了类似的技术点。
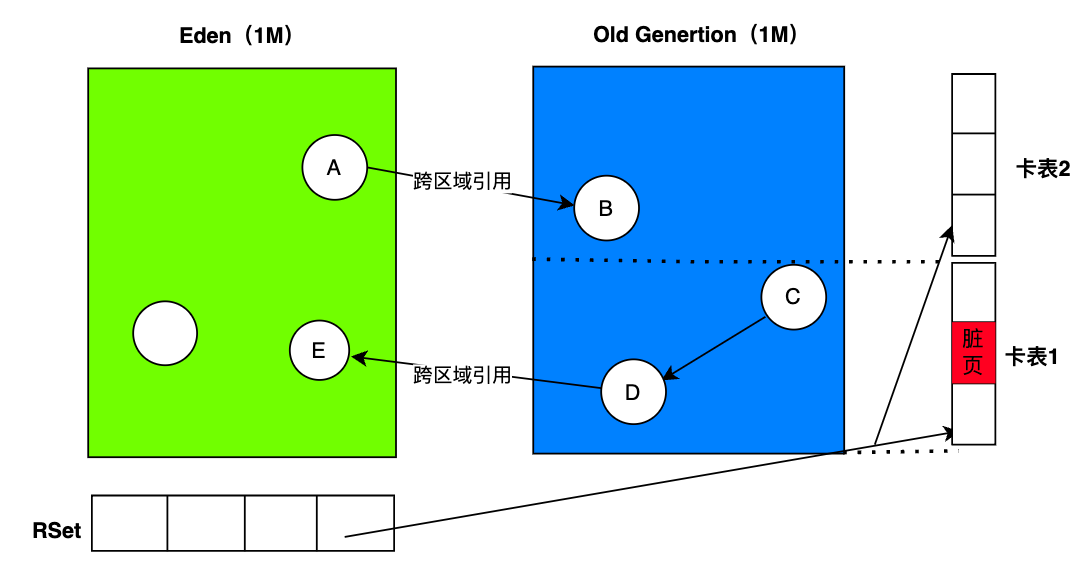
在 CMS收集器中,存在跨代引用的问题,在 G1收集器中也存在同样的问题:跨区域引用,可能因为 G1堆内存有很多的 Region,所以这个跨区域引用的问题似乎表现的更明显。
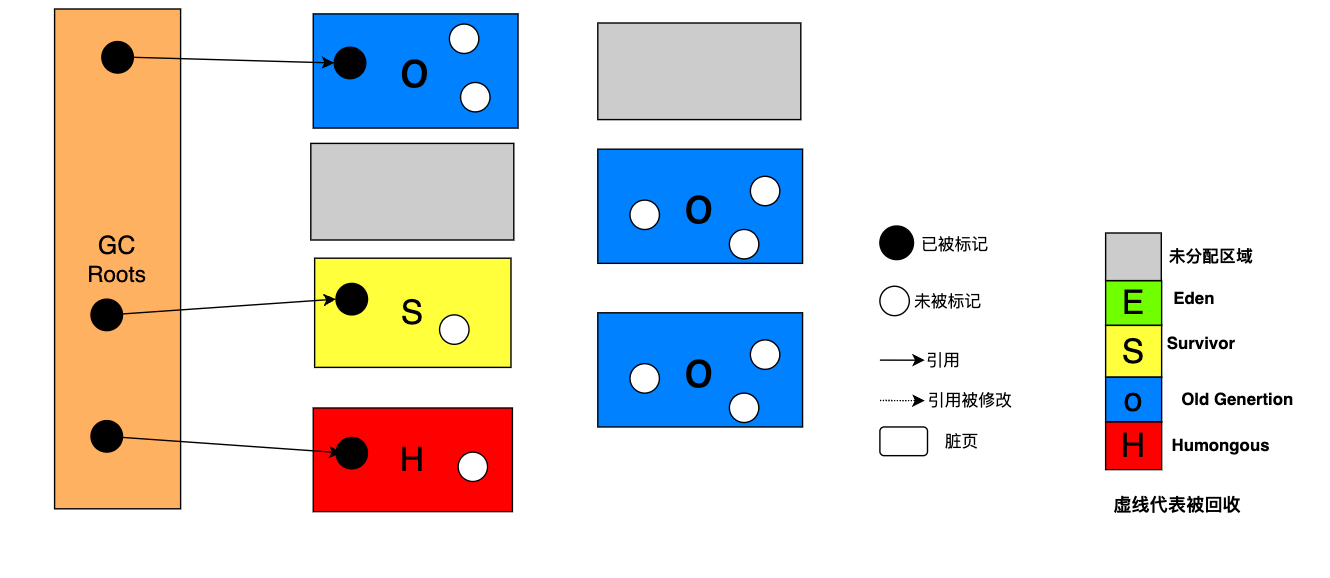
什么是跨区域引用?
如下图:Eden区的 A对象引用 Old区的 B对象,这是一种跨区域引用,Old区的 D对象指向 Eden区域的 E对象,这也是一种跨区域引用。
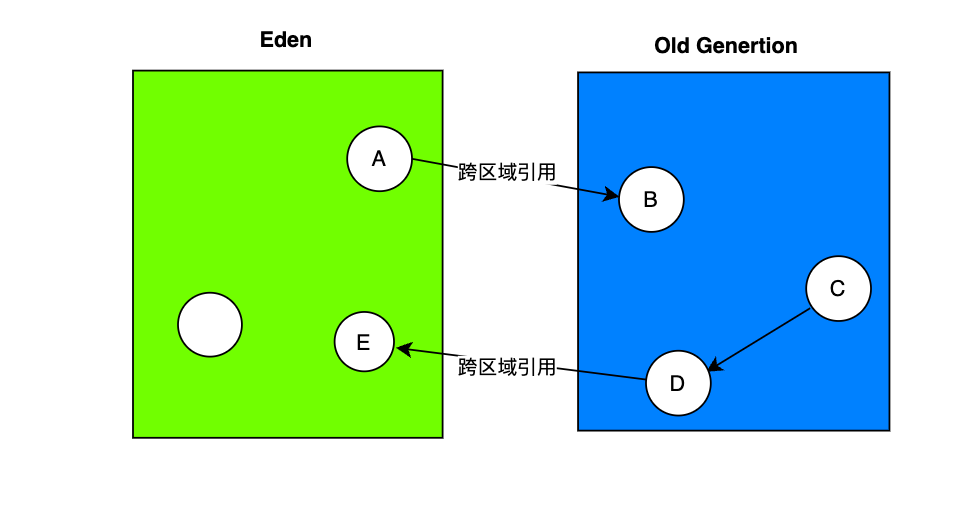
对于上图中 Eden区域(年轻代)A对象指向老年代 B对象,即便 Young GC把 A对象回收了,程序还能正常运行,随着 A->B引用链的断开,B对象最终也可能因为无法被标记被回收,这种行为是可以接受的。
但是,对于老年代 D对象指向 Eden区域(年轻代)E对象的场景,因为老年代 D对象是一个活跃对象,它是一个 GC Root,
所以,D对象直接关联的 E对象也应该是存活对象,假如 E对象被 Young GC掉,就会出现存活的对象无故消失,该如何避免呢 ?
方法1:在 Young GC时扫描所有的老年代,找出指向 E对象的引用,因为 G1是用于大内存的垃圾回收器,如果全局扫描老年代区域,将会是一个很耗时的操作,显然和 G1的设计初衷相违背。
方法2:把老年代指向年轻代(A -> B)的引用关系记录起来,GC时只要扫描这些记录数据,而 G1就是采用这种方式。
在 G1中, 这种关系数据叫做记忆集(Remembered Set,RSet,RS),对于这里 A -> B里面的 B,G1也有专门的术语叫收集集(Collection Set)。
收集集(Collection Set)
在 G1中,收集集(Collection Set,CSet,CS)是指那些将要被清理以回收空间的源区域(Regions)的集合。根据垃圾回收的类型,收集集包含不同种类的区域:
Young-Only阶段:在这个阶段,收集集只包含年轻代中的区域,以及那些可能被回收的巨型(Humongous)区域中的对象。
空间回收阶段:在这个阶段,收集集包括年轻代区域、可能被回收的巨型区域中的对象,以及从候选收集集区域集合中选出的一些老年代区域。
候选收集集区域(Collection Set Candidate Regions)是指那些在空间回收阶段很可能被回收的区域。
G1 会根据区域存活对象的数量以及和其他区域的连接性两个指标进行选择。 存活对象少,连接性低的区域会优先成为候选收集集区域,这种选择的目的是为了优化垃圾回收过程的效率,减少暂停时间,同时最大化回收空间。
记忆集(Remembered Set)
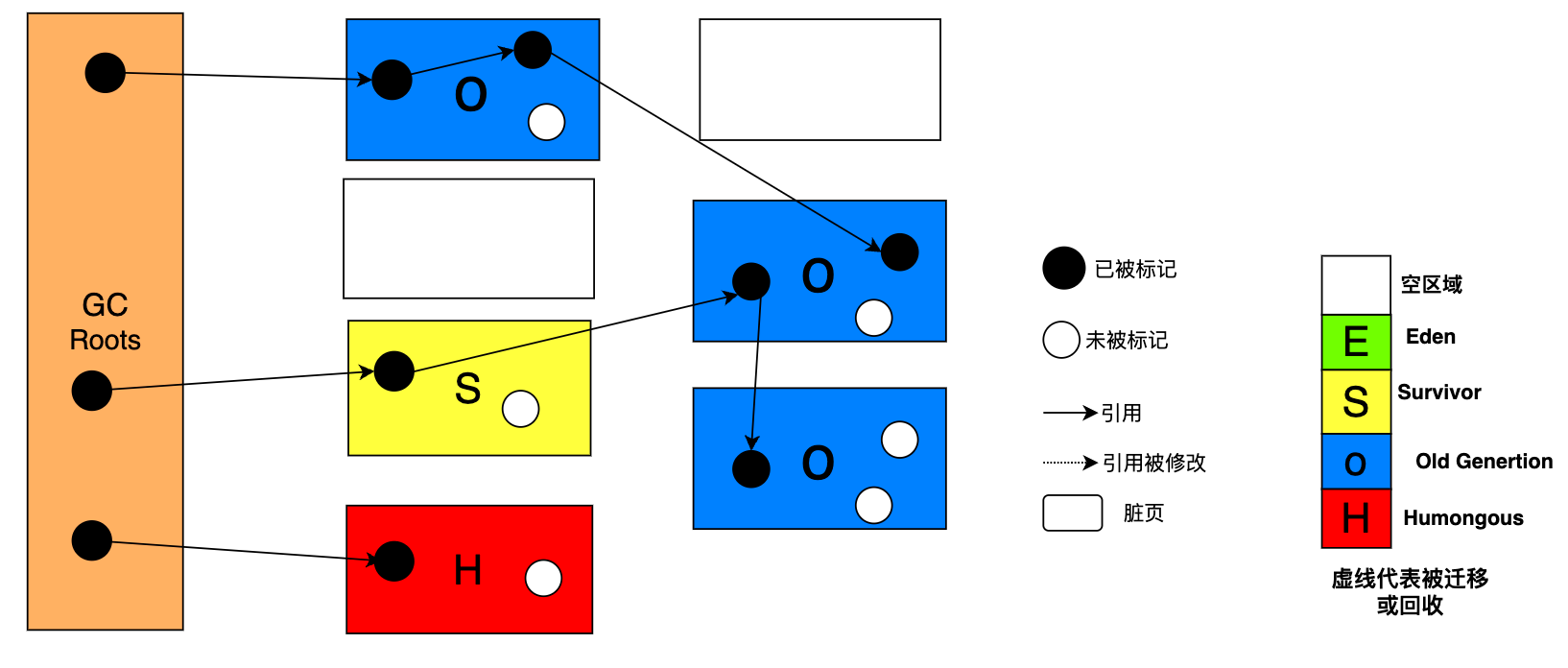
在 G1中,记忆集(Remembered Set,RSet,RS)本质上是一种哈希表,它用于跟踪那些包含指向收集集中对象的引用的位置,这些引用是通过 Cards Table(卡表)来管理。
因为 Region的角色(Eden,Survivor,Old,Humongous)是动态变化的,所以 G1会给每个 Region设置一个 RSet,RSet本质上是一种哈希表,Key是 Region的起始地址,Key对应的 Value是一个集合,里面存储的元素是卡表的索引号。
如下图:Eden是一个收集集,包含一个记忆集(RSet),RSet 指向了两个 Old区域。
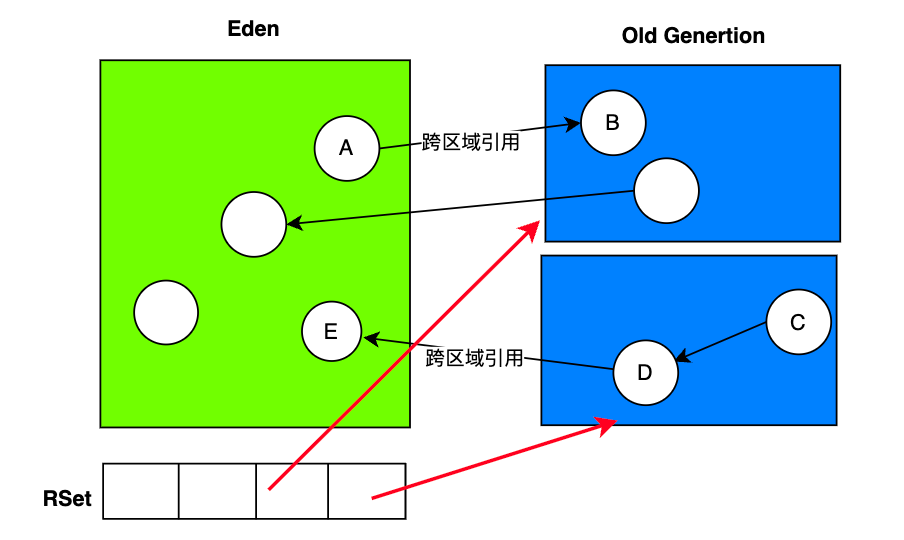
记忆集的作用:
- 为了防止整个堆作为GC Roots的扫描范围
- 确保在垃圾回收过程中,当收集集中的对象被移动,所有指向这些对象的引用都能够更新,指向对象的新位置
记忆集通常是懒惰创建的,也就是说,在 Remark和 Cleanup暂停之间,G1会重建所有候选收集集区域的记忆集。
除此之外,G1始终为年轻代区域维护记忆集,因为这些区域在每次垃圾回收时都会被清理,并且对于一些巨型对象(Humongous Objects),G1默认会进行急切回收,以此来提前释放大块内存。
卡表
卡表(Card Table)是记忆集的一种具体实现,每个 Region被分成了若干个大小为 512字节的连续内存区域,即卡表(Card Table),因为 Region的大小是 1~32M,所以每个 Region中卡表数量是 2~64个。
当一个老年代区域中的对象被修改,比如更新了一个引用字段指向一个年轻代对象时,JVM会使用写屏障(Write Barrier)将相应的卡片标记为“脏”(Dirty)。
在执行 Young GC时,G1会检查这些卡表并找出所有的脏卡片,然后只扫描这些脏卡片对应的内存区域,以更新老年代到年轻代的引用,避免每次 Young GC时都会扫描整个老年代。
如下图:假设 Region的大小为 1M,因此每个 Region就包含 2个卡表。 对象D 指向对象E,对象 E所在的 Eden是一个收集集,它会包含一个 RSet,RSet里有一个 Entry(Key)指向对象 D所在的 Old区域的起始地址,这个 Key对应的 Value包含了卡表的信息。
好了,有了上述几个知识点的铺垫,接下来正式进入 G1 工作流程讲解环节。
G1 工作流程
两条主线
为了更好地讲解 G1回收过程,我特地整理了官方文档的两条主线(或者说两个维度):回收过程 和 回收周期。
回收过程
回收过程是指 G1回收过程中会经历哪些具体的步骤,从全局上看,包括年轻代回收(Young GC),老年代并发标记周期(Concurrent Marking Cycle),混合回收(Mixed GC)和 Full GC 4个过程。
而老年代并发标记周期(Concurrent Marking Cycle)又包含以下 5个过程:
- Initial Marking(初始标记)
- Root Region Scanning(根据扫描)
- Concurrent Marking(并发标记)
- Remark(重新标记)
- Copying/Cleanup(清除垃圾)
从回收过程角度,G1工作流程可以抽象成如下示意图:
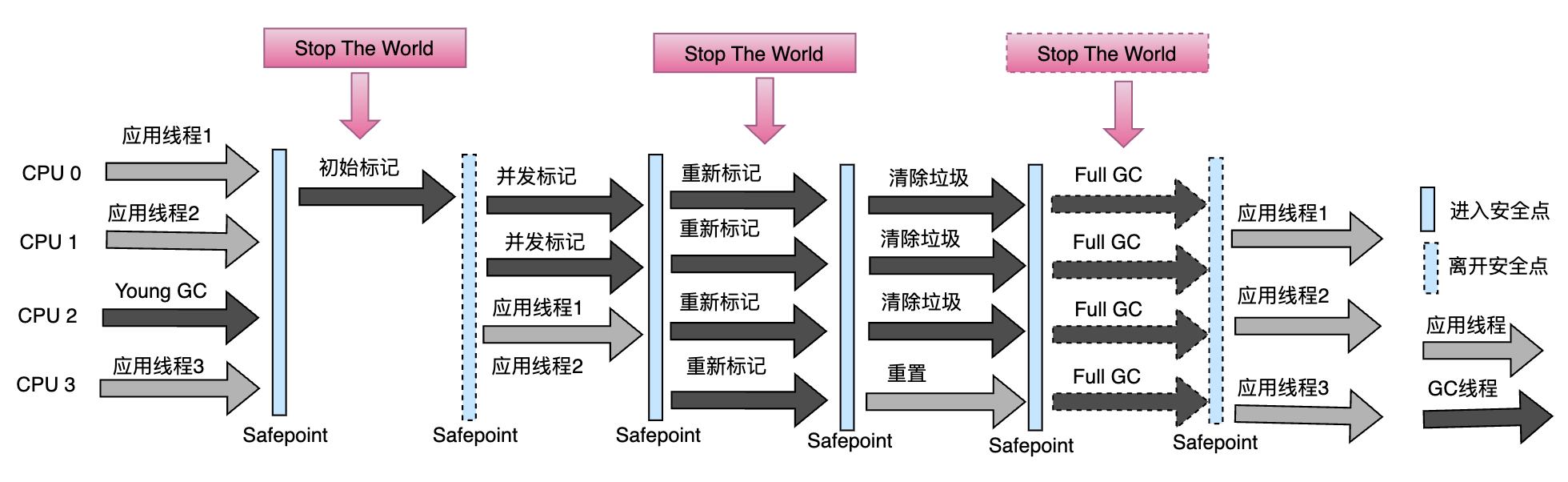
严格意义上讲,Full GC并不能算是一个必须过程,它是 G1设计时需要尽量避免的,但因为这个点比较重要,所以还是把它放在过程中。
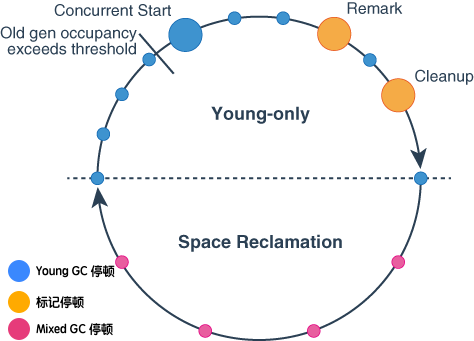
回收周期
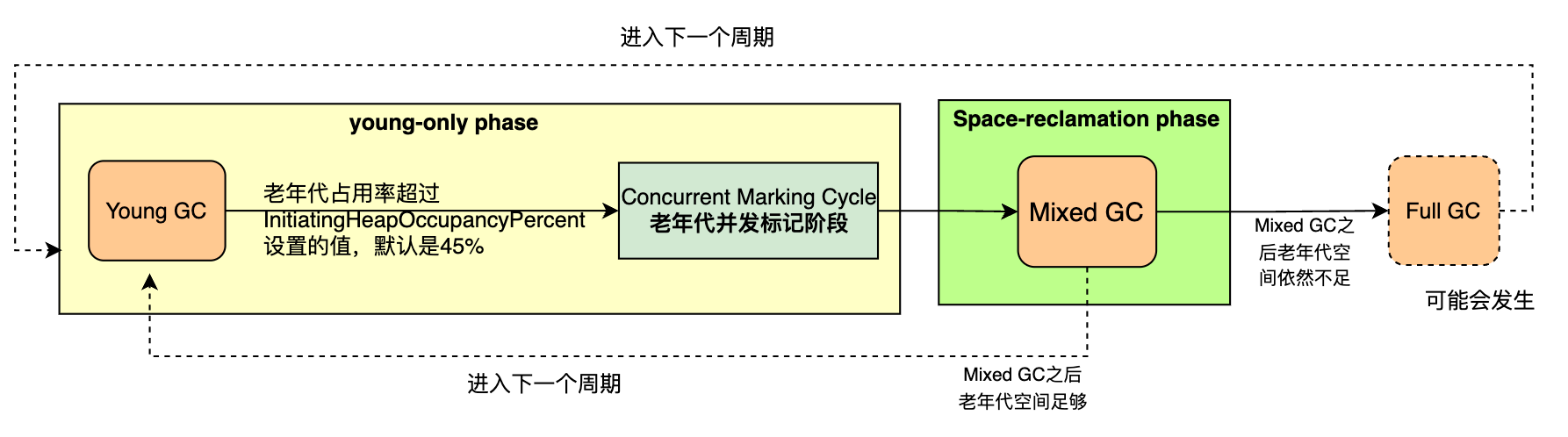
回收周期是对应官方文档的“On a high level”,它是对回收过程更高一层的抽象,包括 Young-only phase 和 Space-reclamation phase 两个阶段。
Young-only phase:这里的“Young-only”是指垃圾收集器只会回收年轻代,该阶段主要完成回收过程中的 年轻代回收(Young GC) 和 老年代并发标记周期(Concurrent Marking Cycle) 两个过程。
Space-reclamation phase:空间回收阶段,该阶段会进行多次年轻代收集(Young GC)以及增量回收部分老年代,被称为混合收集(Mixed GC)。
当 G1判断继续回收老年代不足以释放更多的空间,或者停顿时间大于 MaxGCPauseMillis(默认 200ms)时,会退出该阶段。空间回收阶段对应回收过程中的混合回收(Mixed GC)。
从回收周期角度,G1的工作流程可以抽象成如下示意图:
扁平化后的示意图:
最后,我们从回收过程和回收周期两个维度进行对比,G1的工作流程可以抽象成如下示意图:
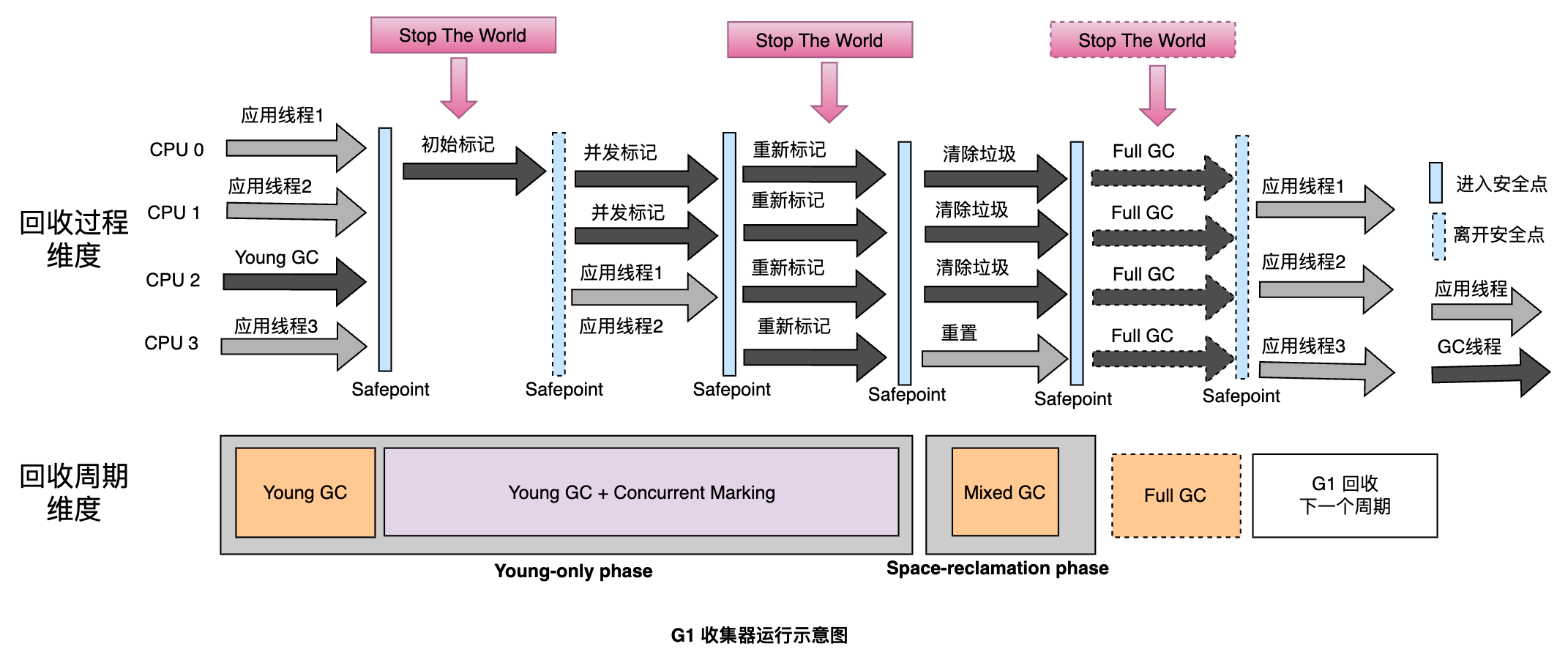
G1的实现细节比较难懂,但是我们可以通过上述两条主线,从整体上去把握 G1,接下来,我们将逐步来分析 G1的工作流程。
回收过程详解
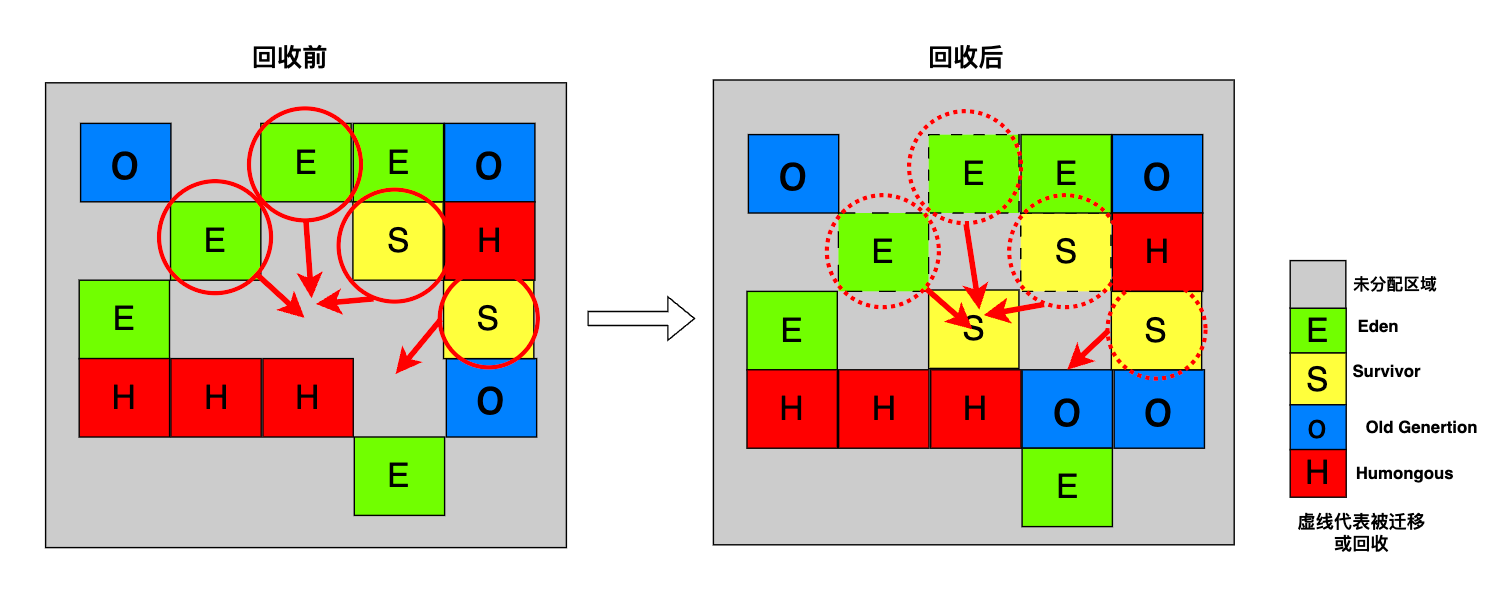
年轻代回收
年轻代回收,顾名思义就是对年轻代的回收,它是一个 Stop The World的过程,当 Eden区的剩余空间无法完成新对象的分配时会触发 Young GC,年轻代回收包含对 Eden区 和 Survivor区的回收,
具体表现为存活对象被复制或移动到一个或多个 Survivor区域,如果对象存活时间达到进入老年代(Old Generation)的阈值,对象将被提升到老年代。
G1 Young GC回收过程示意图如下:
老年代并发标记周期
Initial Mark(初始标记)
初始标记阶段会 Stop The World(STW),但耗时很短,它是伴随 Young GC同步完成的。
初始标记主要完成 2件事情:
- 标记 GC Roots直接关联的对象
- 标记出所有的 survivor区(Root区)
下图为一个简单的初始标记过程示例:
为什么初始标记会搭载 Young GC?
最大的考虑是性能问题,这里给出两个具体的理由:
- 减少停顿时间:Young GC会 Stop The World,而初始标记刚好借着这个停顿时间,做一些额外的标记工作,从而减少 STW的时间;
- 提升效率:Young GC是回收年轻代,而初始标记是标记年轻代和老年代中存活的对象。两者结合,就可以把处理年轻代这个重叠的过程给复用了,提高垃圾收集的效率;
Root Region Scanning(根区扫描)
根区扫描主要是扫描 Survivor区指向老年代的引用。扫描线程和用户线程是并发执行的,
另外,该过程必须在下一个 Young GC到来之前完成,主要原因是 Young GC会涉及到存活对象的在 Region间的移动,
因此,可能会改变 Survivor指向老年代的引用,从而影响数据的正确性。
Concurrent Marking(并发标记)
这里的并发是指 GC线程和用户线程可以并发执行,并发标记阶段的耗时会较长一些。
并发标记主要完成 3件事情:
- 从 GC Root开始,对堆中所有对象进行可达性分析,确认需要回收的对象
- 更新卡表
- 标记空的 Region
并发标记示意图如下:
Remark(重新标记)
重新标记主要完成两件事情:
- 回收并发标记过程中的空 Region
- 利用 Snapshot-At-The-Beginning (SATB) 修正并发标记中的数据,参考:《肝了一周,彻底弄懂了 CMS收集器原理,这个轮子造的真值! 》
Cleanup(清理阶段)
这个阶段主要完成 3件事情:
- 对存活对象进行统计并完全释放空闲区域。(STW)
- 清理记忆集(Remembered Sets)。(STW)
- 重置空闲区域并将它们返回到空闲列表。(并发执行)
混合回收
当老年代的堆使用率达到参数 -XX:InitiatingHeapOccupancyPercent 设定阈值(默认是 45%),
则触发混合回收,混合回收阶段会进行多次 Young GC 以及对部分老年代进行增量回收。
Full GC
Fu1l GC 是 G1最后的防护线,它本是 G1设计时需要尽量避免的,严格上说,不应该作为一个过程来讲,但是 Full GC是实际生产中大家比较关注的问题,所以作为一个过程来分析。
G1 主要通过以下几个参数和指标来决定是否需要触发Full GC:
-XX:G1HeapWastePercent:堆中可以容忍的最大垃圾比例。如果在 Mixed GC之后,垃圾的比例超过了这个阈值,G1可能会触发 Full GC来回收更多的空间。
-XX:G1MixedGCLiveThresholdPercent:当 Old区中的对象占用的比例超过多少时,这部分区域会被包含在 Mixed GC中,默认 85。如果这个比例设置得太低,可能会导致过多的 Old区域被包含在 Mixed GC中,进而增加GC的工作量和停顿时间,最终可能引发 Full GC。
-XX:G1MixedGCCountTarget:在开始进行 Full GC之前,可以执行的 Mixed GC的最大次数。如果连续的 Mixed GC没有有效地回收内存,达到这个次数限制后,G1可能会触发 Full GC。
-XX:G1ReservePercent:保留的堆内存的百分比,默认是10,作为一个缓冲区来减少 Full GC的发生。如果可用内存低于这个阈值,G1可能会触发 Full GC。
为什么 G1 能替代 CMS
接下来,我们呼应文章标题:G1为什么能替代 CMS收集器?我觉得最核心的两个因素是:设计思想更好 以及 算法更优。
设计思想
思想决定高度,对于垃圾回收器也一样,G1 的三个优秀的设计思想,为后面的垃圾收集器(ZGC)奠定了坚实的基础:
- 基于 Region 的内存布局
- 面向局部收集的设计思想
- GC停顿时间和吞吐量的平衡
Region化整为零,面向局部收集的思想完全碾压了 CMS这种需要收集整个老年代的设计。
基于 Region可以同时兼顾年轻代和老年代的回收,而 CMS只能回收老年代。
基于 Region,因为回收的粒度更细,范围更小,使得 G1的停顿时间更加可预测。
实际生产中,并非全部是非此即彼的选择题,很多时候是即要…又要…,因此,CMS为了追求低延时,牺牲了吞吐量,这显然和这种即又场景格格不入。
而 G1则吸取了 CMS的经验教训,尽量做到 GC停顿时间和吞吐量的平衡,它更符合当代大内存的场景需求。
算法
CMS使用的是标记-清除算法,这种算法的最大缺点是产生内存碎片,当内存碎片过多,无法找到足够的连续空间来分配新对象,就会产生一次并发模式失败(Concurrent Mode Failure),启动 Full GC,
而 G1采用的是标记-整理算法,在每次垃圾回收后会进行内存压缩,因此,不会产生内存碎片,便于新生对象的分配。
当然,还有其他一些的性能提升也促成了 G1能替换 CMS,这里就不一一列举了。
总结
因为 G1涉及的知识点太多,所以本文通过两条主线(回收过程和回收周期)进行讲解,作为普通的开发,
个人觉得能够把握 G1的整体流程和一些重要的技术点以及掌握重要的调优参数,就 OK了。
本文同时分析了 G1为什么能替代 CMS回收器,最核心是设计思想以及算法,其他的一些功能也多少有影响。
为了更好的阅读本文,建议先阅读《肝了一周,彻底弄懂了 CMS收集器原理,这个轮子造的真值! 》这篇文章。
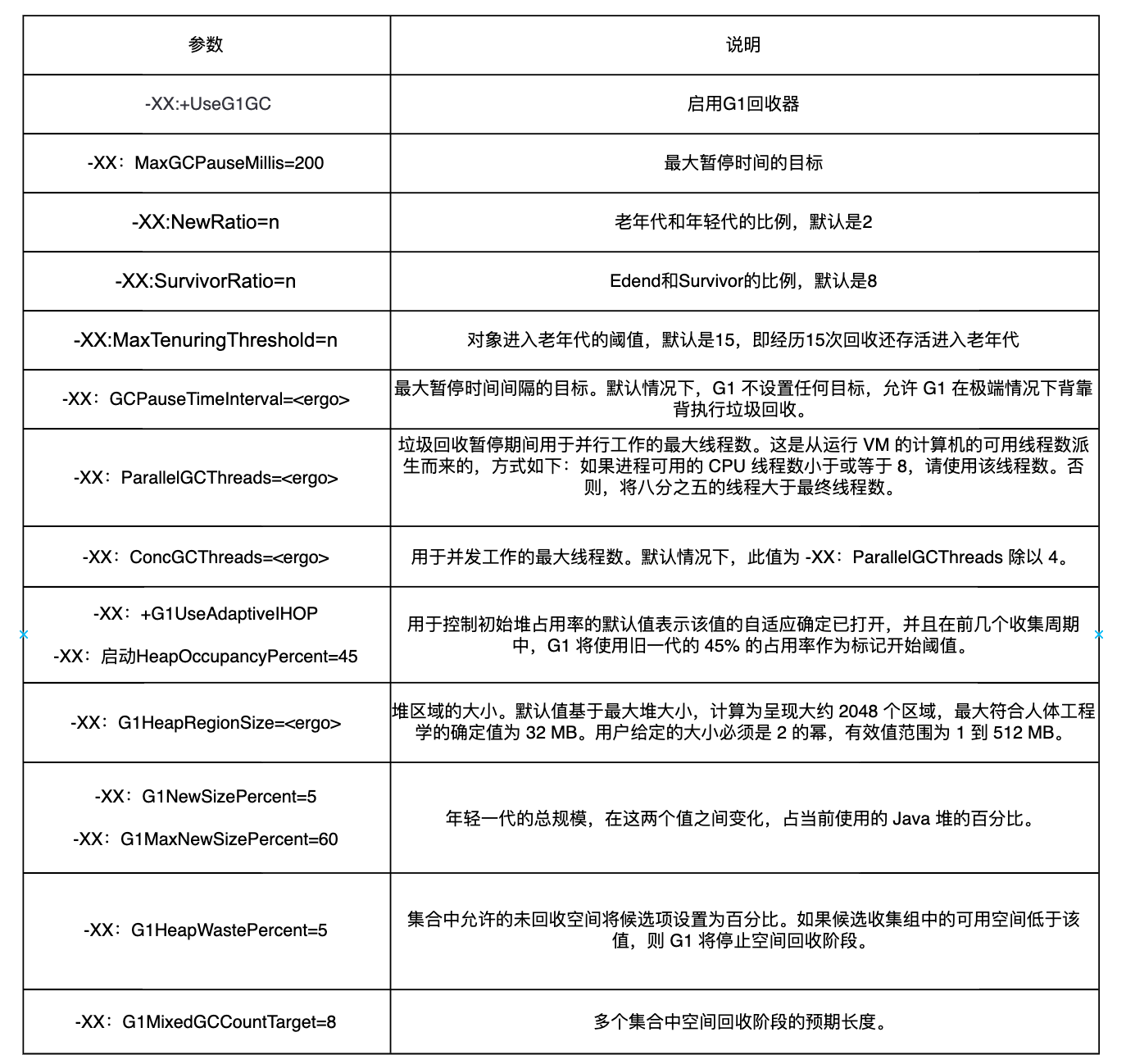
附录一:G1常用参数说明
附录二:JDK各版本 G1的优化点
JDK 7
G1垃圾收集器首次引入,作为一种新的实验性垃圾收集器,主要目标是提供一个可预测的停顿时间以及适应大内存和多核心处理器的系统。
JDK 8
- 提升了性能和稳定性。
- 引入了并行回收模式,允许在回收过程中使用多个线程。
JDK 9
- G1收集器成为默认的垃圾收集器。
- 增加了对字符串去重的支持,减少了内存占用。
- 增加了诊断命令以监控和调试垃圾回收过程。
JDK 10
- 引入了并行完全垃圾回收,提高了大堆回收效率。
- 增加了对应用程序延迟的控制,允许设置最大停顿时间目标。
JDK 11
- 进一步优化性能,降低了停顿时间。
- 增加了对实验性的低延迟垃圾收集器ZGC的支持。
- 增加了对无操作垃圾收集器Epsilon的支持。
JDK 12
G1收集器增加了一个新的特性,即并发类卸载,这有助于在垃圾回收期间减少停顿时间。
JDK 13
G1收集器在JDK 13中没有显著的新变化。
JDK 14
G1收集器增加了JEP 345特性:NUMA-Aware Memory Allocation for G1,提高了在NUMA系统上的性能。
JDK 15
G1收集器在JDK 15中没有显著的新变化。
JDK 16
G1收集器引入了JEP 376: ZGC: Concurrent Thread-Stack Processing,这是ZGC的一个特性,但对G1的并发处理能力也有提升。
JDK 17
- G1收集器增加了自动调整的启动堆占用特性。
- G1收集器的停顿时间日志现在包括更详细的信息。
JDK 18
G1收集器引入了JEP 421: Deprecate Finalization for Removal,这意味着G1将逐步淘汰对象终结器的使用。
JDK 19~21
G1收集器没有显著的新变化。
JDK 22
- G1 (JDK-8140326) 会在下一次任何类型的垃圾回收中回收疏散失败的区域。这提高了 G1 收集器的恢复能力,避免其旧版本被疏散失败的区域淹没。
- 在 G1 中取消 GCLocker 使用的漫长旅程已经结束。
- 优化了回收算法
- Remark 暂停期间的堆大小调整有一些小改动,以使调整大小更加一致
附录三: 参考资料
http://cs.williams.edu/~dbarowy/cs334s18/assets/p37-detlefs.pdf
https://www.oracle.com/java/technologies/javase/hotspot-garbage-collection.html
https://www.oracle.com/technetwork/java/javase/memorymanagement-whitepaper-150215.pdf
https://tschatzl.github.io/
https://dl.acm.org/doi/10.1145/1029873.1029879
https://ssw.jku.at/Teaching/MasterTheses/Protopopovs/Thesis.pdf
https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
https://tschatzl.github.io/2022/08/04/concurrent-marking.html
https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/toc.html
https://docs.oracle.com/javase/9/gctuning
https://docs.oracle.com/javase/10/gctuning
https://docs.oracle.com/en/java/javase/11/gctuning
https://www.youtube.com/watch?v=2PIBF92iOvQ
https://www.youtube.com/watch?v=Gee7QfoY8ys
JDK 11以上版本的G1,地址只需要把 JDK11中地址里面的 11 替换成目标版本就可以了,也可以在下面的地址里面查找:
https://docs.oracle.com/en/java/javase/
交流学习
如果文章存在缺点和错误,欢迎批评指正。更多干货和面试经,关注公众号:猿java。
