你好,我是猿java。
上篇文章我们分享了DynamoDB的本地二级索引,既然有了本地二级索引,为什么还需要全局二级索引?两者之间有什么相似点和区别呢?今天我们就来一起聊聊。
概念
全局二级索引本质上是一种数据结构(类同于mysql中的索引的概念)。每个全局二级索引必须和一个表关联,这个表称为索引的基表,索引可以包含基表中的某些或者全部属性。
如下图,可以把索引看作和表一样的数据结构,这样我们就能可以使用Query或者Scan从索引中检索数据。
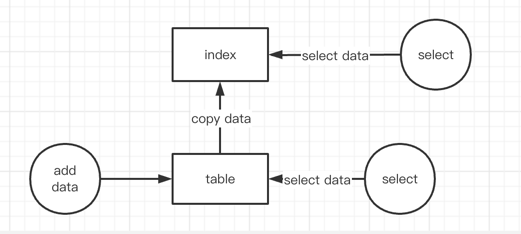
创建二级索引时,从基表投影或复制到索引中的属性,一般包含三种模式:
- 所有字段模式:基础表的所有属性都投影到索引中
- 只有keys模式:只有索引和主键被投影到索引中
- 包含模式:索引和主键以及额外指定的其他非键属性
为什么需要全局二级索引
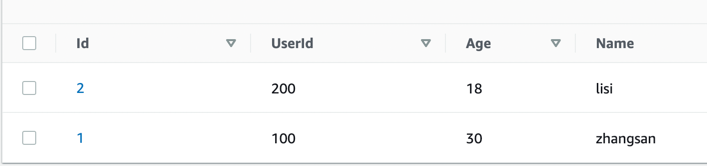
比如下面的一张User表,Partition key为Id,Sort key为UserId,查询的场景是:Age为18,Name包含’张’的所有用户,我们就不得不全表扫描表,当表的数据达到千万甚至更大时,
这将会消耗大量的时间,如何快速的查询结果?给Age和Name字段增加一个索引,这就是DynamoDB的二级索引。
全局二级索引的创建
创建全局二级索引的方式有多种,这里提供3种常见的方式:控制台、aws指令、代码。
控制台
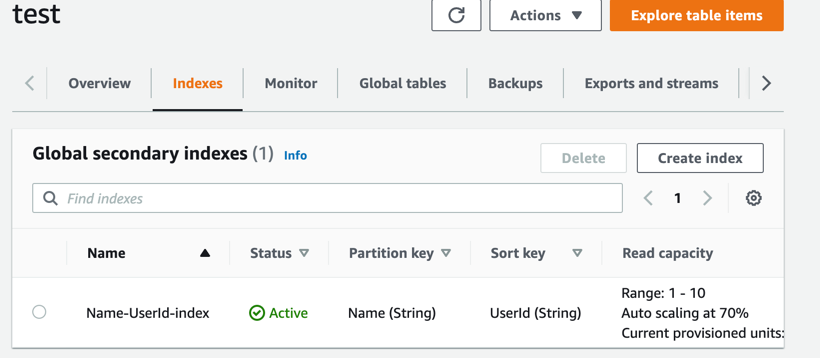
控制台的有点就是能可视化创建,操作可以参考下图:
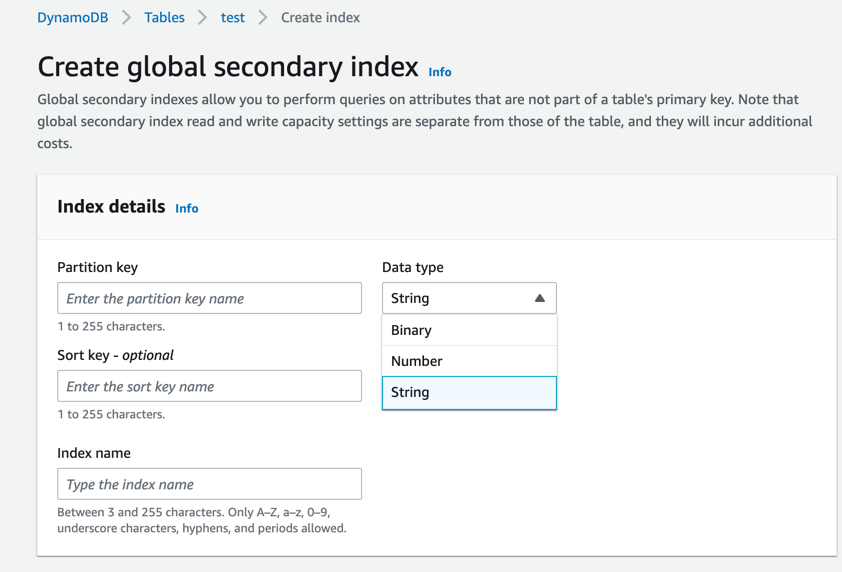
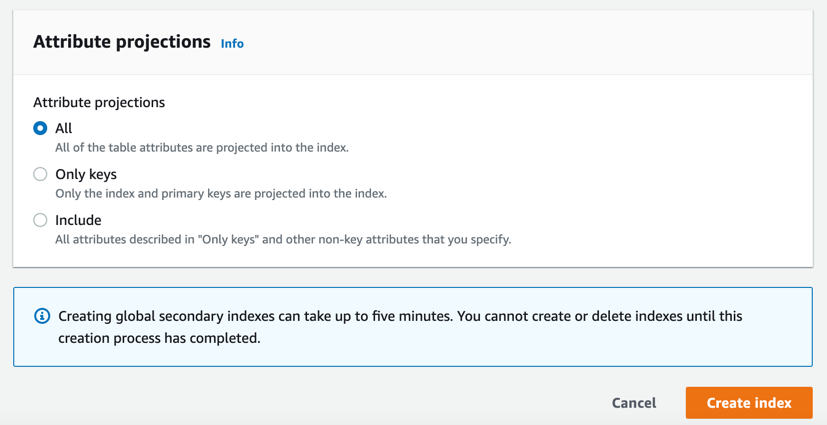
这里的Partition key和基表复合主键中的Partition key不能相同,Sort key为可选项,比如:我这里填写的是Age, 点击Create index按钮,全局二级索引就创建完成:
aws指令创建
aws指令是亚马逊提供的一套本地操作产品的指令,有点类似mysql的client指令,我们可以参考官方文档进行安装
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| $ aws dynamodb create-table \
--table-name test \
--attribute-definitions '[
{
"AttributeName": "Id",
"AttributeType": "S"
},
{
"AttributeName": "Age",
"AttributeType": "N"
},
{
"AttributeName": "Name",
"AttributeType": "S"
}
]' \
--key-schema '[
{
"AttributeName": "Id",
"KeyType": "HASH"
},
{
"AttributeName": "Age",
"KeyType": "RANGE"
}
]' \
--global-secondary-indexes '[
{
"IndexName": "Age-index",
"KeySchema": [
{
"AttributeName": "Id",
"KeyType": "HASH"
},
{
"AttributeName": "Age",
"KeyType": "RANGE"
}
],
"Projection": {
"ProjectionType": "KEYS_ONLY"
}
}
]' \
--provisioned-throughput '{
"ReadCapacityUnits": 1,
"WriteCapacityUnits": 1
}' \
|
代码
1
2
3
4
5
6
7
| GlobalSecondaryIndex precipIndex = new GlobalSecondaryIndex()
.withIndexName("PrecipIndex")
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 10)
.withWriteCapacityUnits((long) 1))
.withProjection(new Projection().withProjectionType(ProjectionType.ALL));
|
全局二级索引的使用
在上文中我们创建了一个全局二级索引 Age-Name-index,我们需要使用该全局二级索引从test表中查询age=30,名字=张三的所有用户,java代码例子如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public class Test {
public Optional<PublicResourceModel> findByUserIdResourceId(String userId, String resourceId) {
HashMap<String, AttributeValue> eav = Maps.newHashMap();
eav.put(":age", new AttributeValue().withS(userId));
eav.put(":name", new AttributeValue().withS(resourceId));
DynamoDBQueryExpression<PublicResourceModel> queryExpression = new DynamoDBQueryExpression<>();
queryExpression.setIndexName("Age-Name-index");
queryExpression.setConsistentRead(false);
queryExpression.withKeyConditionExpression("Age= :age and Name= :name");
queryExpression.withExpressionAttributeValues(eav);
queryExpression.withLimit(1);
PaginatedQueryList<PublicResourceModel> list = SpringContextUtil.getDynamoDBMapper().query(PublicResourceModel.class, queryExpression);
if(!CollectionUtils.isEmpty(list)){
return Optional.of(list.get(0));
}
return Optional.empty();
}
}
|
注意事项
- 全局二级索引与基表拥有不同的分区键(Partition key), 排序键(Sort key)可以相同也可以不相同;
- 全局二级索引可以在创建基表时创建,也能在现有表上去添加;
- DynamoDB会自动维护全局二级索引,当表中有增、删、改操作时,DynamoDB会利用最终一致的模型异步把数据的变动维护到索引中;
- 全局二级索引将会继承基表的读写容量(读写容量是在创建表示设置的参数)
- 创建全局二级索引时,指定了分区键和排序键的类型,因此在往基表中增加数据时,类型必须和全局二级索引中字段类型保持一致,否则抛出ValidationException异常;
- 全局二级索引越多花费的费用越多
全局二级索引和本地二级索引的比较
本地二级索引必须和基表拥有相同的Partition key,而全局二级索引和基表的Partition key不能相同;
本地二级索引对应的基表必须是符合主键,而全局二级索引不做限制;
本地二级索引必须和基表一起创建,而全局二级索引可以和基表一起创建,也可以在基表创建好之后创建;
参考文档
AWS DynamoDb官方文档
学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
