
心跳机制在分布式系统中是如何工作的?
嗨,你好呀,我是猿java
在很多分布式系统中,我们经常看到它们使用心跳机制,为什么这么多的分布式系统使用心跳机制?心跳机制到底是什么?今天就来聊一聊。
什么是心跳机制?
在分布式系统中,心跳其实就是从一个组件发送到另一个组件的定期消息,用于交换数据或者健康状态,心跳可以是单向的,也可以是双向的。
单向心跳包
单向心跳包是由一个节点(发送者)定期向另一个节点(接收者)发送消息,而不要求接收者回复。这种方式简单而高效,适用于一些基本的健康检查和状态监控。
优点:
- 实现简单:发送者只需定期发送心跳包,不需要处理回复逻辑。
- 低延迟:减少了通信的往返时间,适合低延迟应用场景。
缺点:
- 缺乏确认:接收者的状态信息是单向的,发送者无法确定接收者是否收到心跳包。
- 误报风险:如果网络临时中断,接收者无法通知发送者,可能导致误报。
使用场景:
- 基础监控:如定期发送服务器状态信息到监控系统。
- 简单的健康检查:如负载均衡器检查后端服务器是否存活。
双向心跳包
双向心跳包涉及两个节点之间的双向通信。一个节点发送心跳包,接收者收到后回复确认消息。这种方式能够提供更可靠的状态信息。
优点:
- 确认机制:发送者能确认接收者是否收到心跳包,提高了通信的可靠性。
- 状态同步:双方可以交换状态信息,确保数据的一致性和同步。
缺点:
- 实现复杂:需要处理发送和接收的逻辑,增加了系统的复杂性。
- 潜在延迟:增加了通信的往返时间,可能引入一些延迟。
使用场景:
- 故障检测:如数据库主从同步,确保数据一致性。
- 高可靠性应用:如分布式文件系统,确保各节点间的状态同步。
如下图:Server1 向 Server2 发送一条单向心跳消息:
为什么需要心跳机制?
因为分布式系统可能包含很多服务器,形成错综复杂的网络交互,产生的问题也是形形色色,假如没有心跳机制,可能会出现以下问题:
- 无法及时感知故障检测
- 服务器停机时间和错误会增加
- 整体分布式系统的可靠性会降低
增加心跳机制后,可以实现以下功能:
- 监控:心跳消息有助于监控分布式系统不同部分的运行状况和状态。
- 检测故障:心跳机制使系统能够识别组件何时无响应。如果节点错过了几个预期的心跳信号,则表明可能存在问题。
- 触发恢复操作:心跳机制允许系统采取纠正措施,如将任务移动到正常运行的节点、重新启动故障组件或通知系统管理员介入。
- 负载均衡:通过监控不同节点的心跳信号,负载均衡器可以根据每个节点的响应能力和运行状况,更有效地在网络中分配任务。
心跳机制是如何工作的?
心跳机制主要涉及两个主要组件:
- 心跳发送者(节点):定期发送心跳信号的节点。
- 心跳接收器(监视器):接收并监视心跳信号的组件。
心跳机制整个过程包含以下几个步骤:
- 节点定期向监视器发送心跳包,比如每 5/10/30秒发送一次心跳包。
- 监视器接收心跳包,并更新节点的状态,比如“活动”或“可用”。
- 如果监视器在规定的时间范围内未收到节点的心跳包,则会将节点标记为“不可用”或“故障”。
- 系统检测到有异常的节点,需要采取适当的操作,例如重定向流量、启动故障转移过程或向管理员发出警报。
心跳包的发送机制通常上有 2种方式:
- Push方式:节点主动向监视器发送心跳包
- Pull方式:监视器会定期查询节点的状态
如下图为一个简单的心跳健康检查机制: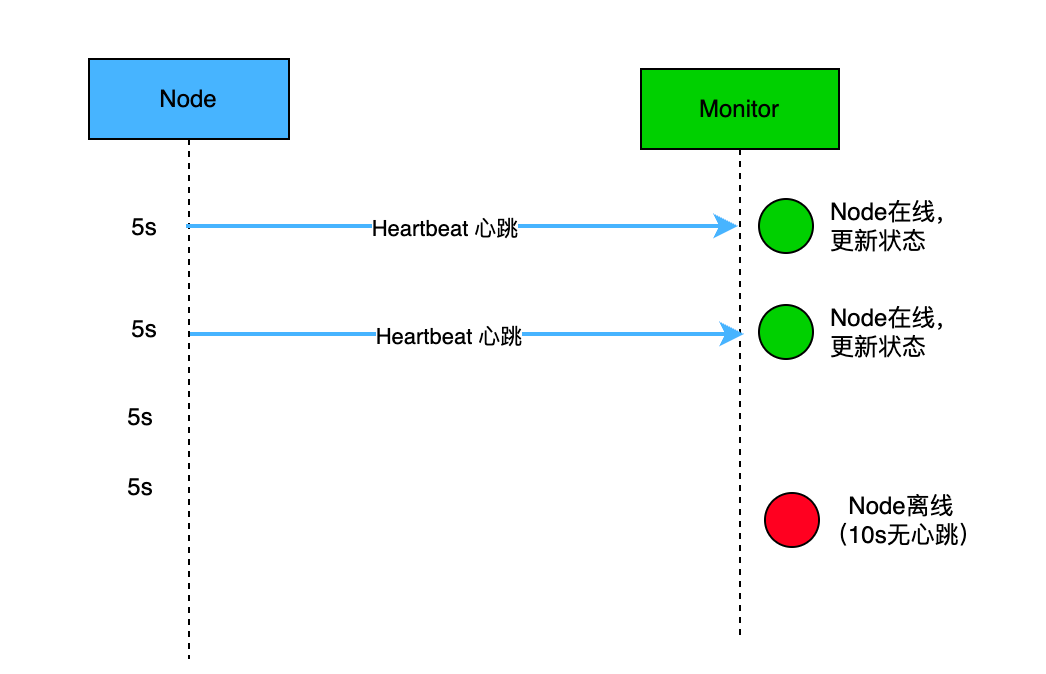
心跳包类型
心跳包在分布式系统中本质上就是一条信息,只不过会根据不同的业务场景定义成不同的类型,以下是常见的心跳包类型:
简单心跳包
- 用途:基本的存在检测。
- 内容:通常包含节点ID和时间戳。
- 示例:节点每隔一段时间发送一个简单消息,告知其仍在运行。
状态心跳包
- 用途:不仅检测节点存在,还报告节点状态。
- 内容:包含节点ID、时间戳、CPU使用率、内存使用率、磁盘状态等。
- 示例:节点发送详细的状态信息,使监视器可以评估其健康状况。
负载心跳包
- 用途:报告节点当前负载,以便于负载均衡。
- 内容:包含节点ID、时间戳、当前负载指标(如当前连接数、任务队列长度等)。
- 示例:负载均衡器根据负载心跳包的信息来调整任务分配。
自检心跳包
- 用途:节点自行检查并报告其健康状态。
- 内容:包含节点ID、时间戳、自检结果(如服务健康检查结果、错误日志摘要等)。
- 示例:节点定期运行自检脚本,并将结果发送给监视器。
同步心跳包
- 用途:用于多节点之间的状态同步。
- 内容:包含节点ID、时间戳、同步状态、最新数据版本等。
- 示例:数据库集群中的主节点与从节点之间使用同步心跳包来确保数据一致性。
事件心跳包
- 用途:通知监视器特定事件的发生。
- 内容:包含节点ID、时间戳、事件类型和事件详细信息。
- 示例:节点在发生重要事件(如重新启动、故障修复)时发送事件心跳包。
安全心跳包
- 用途:增强安全性,确保心跳消息的真实性和完整性。
- 内容:包含节点ID、时间戳、签名信息或加密数据。
- 示例:节点发送的心跳包经过数字签名,监视器验证签名以确保消息未被篡改。
心跳机制面临的问题
因为分布式系统包含了比较多的服务器,而心跳又是在这些服务器之间通过网络传播的,因此,使用心跳包也面临一些挑战:
- 网络拥塞:如果管理不当,心跳信号的持续流动可能会导致网络拥塞。
- 误报:心跳信号间隔配置不当可能会导致故障检测出现误报,误将运行缓慢但正常的组件标识为故障组件。
- 资源使用:持续监控需要计算资源,必须优化以防止对系统造成不必要的压力。
- 脑裂场景:在极少数情况下,网络故障可能会将系统分区,导致双方节点互相宣布对方死亡,这需要更复杂的故障处理机制。
心跳机制的使用场景
心跳机制在分布式系统中有着大量的使用场景,这里列举几个实际工作中最常见的例子:
消息中间件
在消息中间件 RocketMQ中,Broker会通过心跳包和注册中心 NameServer保持交互,这样注册中心就能监控到 Broker的状态,从而给生产者和消费者提供比较实时的 Broker集群列表。
Kubernetes
在 Kubernetes容器编排平台中,每个节点都会定期向控制平面发送心跳,以指示其可用性。控制平面使用这些检测信号来跟踪节点的运行状况,并相应地做出调度决策。
Elasticsearch
在 Elasticsearch集群中,节点交换心跳以形成八卦网络。此网络使节点能够相互发现、共享集群状态信息并检测节点故障。
Redis Cluster
Redis Cluster集群中的心跳包实现基于 Gossip协议,它是一种分布式通信协议,允许节点周期性地与随机选择的其他节点交换状态信息。Redis Cluster的心跳包称为 PING和 PONG消息,主要结构如下:
- PING 消息:用于发送节点的状态信息,包括节点ID、节点角色(主节点或从节点)、槽位信息等。
- PONG 消息:用于响应 PING 消息,确认接收到的状态信息。
总结
心跳机制在分布式系统中起到了重要的作用,因此,了解和掌握心跳机制,对于掌握分布式系统之间如何交互信息和服务器探活有着重要的意义。
交流学习
最后,把猿哥的座右铭送给你:投资自己才是最大的财富。 如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
