如何分析系统的负载?生产排错必备技能
Hi,你好,我是猿java。
作为一名后端程序员,应该能经常听到“系统负载过高”,“CPU打爆了”诸如此类的描述,那么,什么是系统负载过高?什么是 CPU打爆了?生产环境,又该如何排查?今天我们就来聊一聊。
遇到问题时,最重要的一环就是查看问题,下面分析 4个生产环境中会高频使用的查询指令。
如何查看负载
top 命令
top是使用最高频的指令之一,命令及运行截图如下:
1 | # 系统默认安装的命令 |
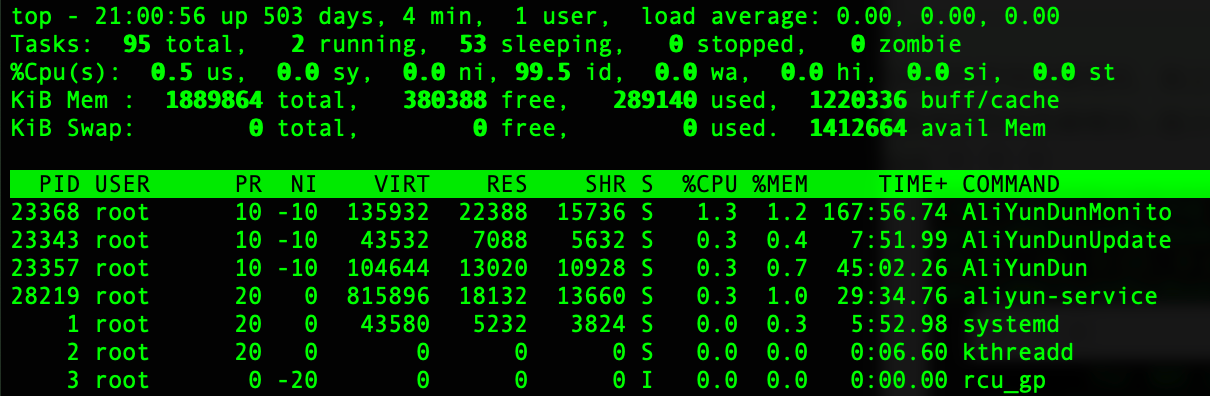
通过执行指令可以看出:top 是交互式的系统监视工具,实时显示的信息特别多,主要包括下面几类:
- 进程信息:
- PID:进程id,唯一标识进程
- 用户:运行进程的用户
- CPU 使用率:进程正在使用的 CPU 资源的百分比
- 内存使用率:进程正在使用的内存的百分比
- 进程状态:进程的状态,如运行、休眠、停止等
- 进程优先级:进程的优先级
- 进程启动时间:进程启动的时间
- 系统总体性能:
- 系统平均负载:1分钟、5分钟和15分钟的平均负载,用于表示系统的负载情况
- 总体 CPU使用率:系统的总体 CPU 使用率
- 总体内存使用:系统的总体内存使用情况,包括总内存、空闲内存、已使用内存等信息
- 总体交换分区使用:如果有交换分区,它的使用情况也会显示
- CPU 利用率:
- 按核心或逻辑处理器显示每个 CPU 核心的使用情况,包括用户态、系统态、空闲时间等
- 内存和交换分区使用情况:
- 物理内存:总物理内存、已使用内存、可用内存、缓存和缓冲区等信息
- 交换分区:总交换空间、已使用交换空间和可用交换空间
- 任务信息:
- 运行中的任务总数、运行任务数、睡眠任务数等
- 系统时间:
- 当前系统时间以及系统运行时间
uptime 命令
top命令显示的信息太多,如果想简单的展示系统负载,uptime是比较匹配的命令,命令及运行截图如下:
1 | # 系统默认安装的命令 |

通过截图可以看出:uptime 命令只会显示系统的平均负载以及系统当前时间、已运行时间和登录用户数量 4个信息。
htop 命令
htop命令,系统默认是不安装的,所以在使用该命令时需要先安装,命令和运行截图如下:
1 | # 系统默认不安装,需要自己安装,比如:apt-get install htop |
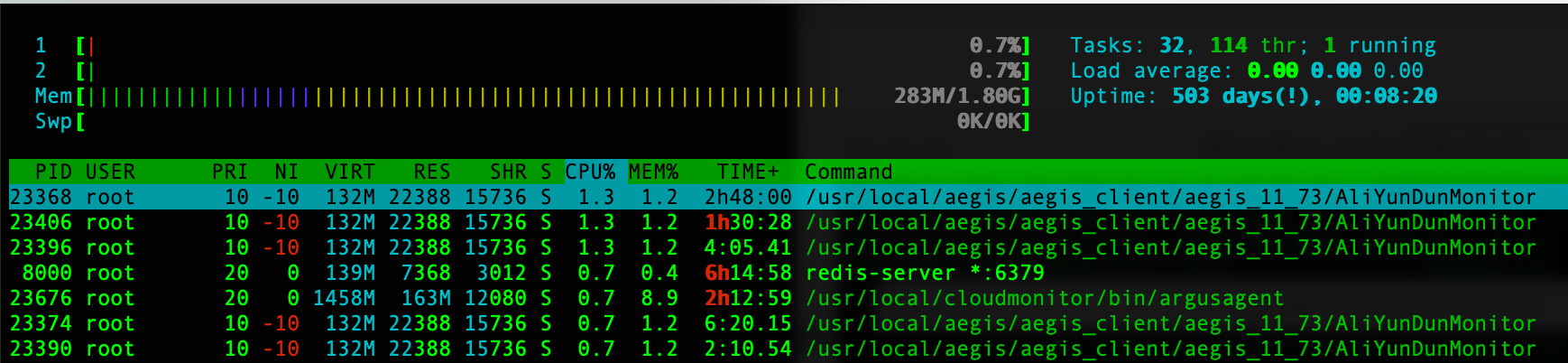
通过执行指令可以看出:htop 和 top很类似,也是交互式的系统监视工具,主要会显示下面8种信息:
进程列表:htop 显示当前运行的所有进程的列表,包括它们的进程ID(PID)、用户、进程状态、CPU 使用率、内存使用量等信息。这些信息按默认情况下按 CPU 使用率降序排列。
CPU 和内存利用情况:htop 在顶部显示了一个可视化的 CPU 和内存利用情况的图形。这些图形可以帮助你直观地了解系统资源的使用情况。
系统负载信息:htop 在顶部的第一行显示了系统的平均负载值,以及CPU核心的使用情况。这包括用户态、系统态和等待态(I/O等待)的负载。
快捷键帮助:htop 在底部显示了一些快捷键的帮助信息,以便用户可以通过键盘快速执行不同的操作,如终止进程、改变排序方式等。
进程树:htop 可以显示进程树,这是一种以树状结构展示进程之间关系的方式,有助于理解进程之间的父子关系。
进程状态标签:htop 使用不同的颜色和标签来表示进程的状态,例如运行中的进程、休眠的进程、僵尸进程等,这有助于快速识别问题。
进程详细信息:通过选中进程并按下键盘上的箭头键或使用其他快捷键,htop 可以显示有关选定进程的更详细的信息,如打开的文件、线程信息、进程环境变量等。
可定制性:htop 允许用户自定义显示的列和排序方式,以满足特定的监视需求。
w 命令
w 命令和 uptime很类似,命令及运行截图如下:
1 | # 系统默认安装 |

通过执行指令可以看出:w 命令会显示当前登录用户的信息,包括平均负载。
通过执行上面 4个指令,我们可以看出:每个指令的结果里面都包含“load averages: 数字1 数字2 数字3”, 那么 load averages是什么? 后面的3个数字又代表什么含义?
平均负载
定义
load averages,中文翻译为:平均负载,它是指在一段时间内系统上运行的进程数量或等待资源的平均情况。通常用于 Unix 和类 Unix 系统。
定义看起来有些晦涩,其实,我们可以把平均负载简单理解成平均活跃进程数。
三个重要数字
介绍了平均负载的定义,接着分析 load averages 后面三个重要数字的含义,通过执行 man uptime指令,我们可以查看官方文档:
1 | # 系统默认安装的命令 |
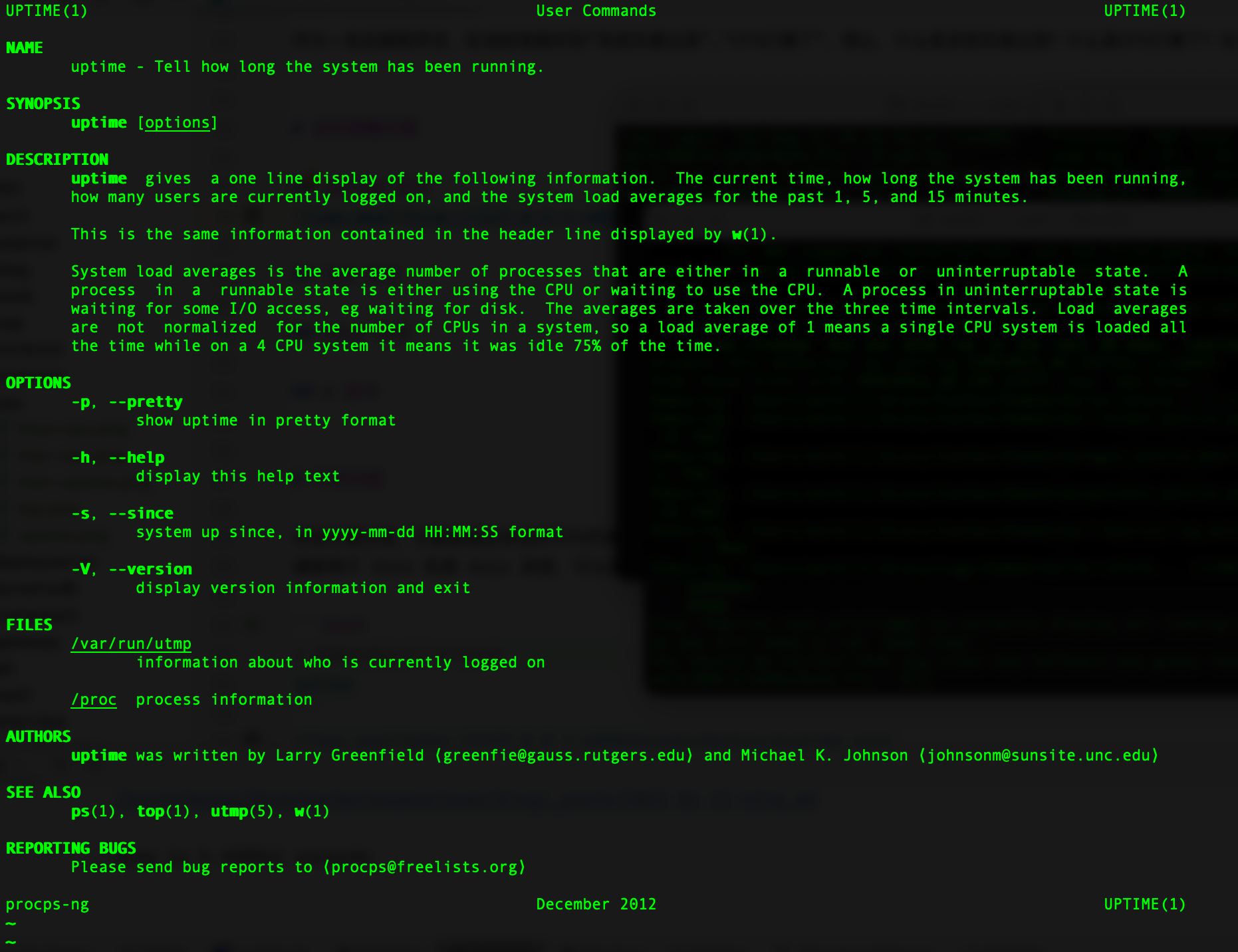
从文档截图可以总结三个数字的含义分别为:
- 1分钟平均负载: 表示在最近1分钟内系统的平均负载情况;
- 5分钟平均负载: 表示在最近5分钟内系统的平均负载情况;
- 15分钟平均负载: 表示在最近15分钟内系统的平均负载情况;
解释完 load averages 3个数字的含义,另一个问题也就随之而来:3个数字的值为多少代表系统健康?多少代表系统过载了?在解答这个问题之前,我们先来分析“CPU打爆了”。
CPU打爆了
CPU打爆了,其实就是说 CPU的使用率大于等于100%,比如,如果服务器只有一个 CPU,100% 就代表 CPU满负载,如果服务器有 2个 CPU,那么 CPU的使用率 >= 200%,CPU就被打爆了,
在生产环境,通常会把CPU总量的 80%~85%设置为报警阈值,这样就能提醒相关人员服务器的 CPU使用过高,需要特别关注。
那么,如何查看服务器的 CPU个数呢? 可以使用下面的指令:
1 | # linux 查看CPU个数 |
如下图:

两者关系
分析了平均负载和 CPU使用率,那么两者之间存在什么关系呢?
在平均负载定义时提到平均负载就是进程平均数,因此,先来看看进程是什么:
进程是指计算机上运行的程序实例,通常包含 CPU密集型进程 和 IO密集型进程,两种进程的详情如下:
- CPU密集型进程:
特点:CPU密集型进程是那些主要依赖于处理器执行能力的任务。它们通常涉及大量的计算、数据处理和算法运算,需要大量的 CPU时间来完成。
资源需求:这种类型的进程主要消耗 CPU资源,而对内存和磁盘等其他资源的需求相对较低。
性能特点:CPU密集型进程在多核处理器上执行时,可以受益于并行计算,因为它们可以同时在多个CPU核心上运行。提高CPU频率和核心数量可以显著提高这些进程的性能。
示例:数值模拟、图像处理、密码破解等计算密集型任务。
- IO密集型进程:
特点:IO密集型进程是那些主要涉及文件读写、网络通信、数据库查询等需要大量IO操作的任务。它们通常不需要大量的CPU计算时间,而是花费大部分时间等待IO操作完成。
资源需求:IO密集型进程对 CPU的需求相对较低,但对存储设备、网络和内存等IO相关资源的需求较高。
性能特点:提高 CPU性能对 IO密集型任务的影响有限,因为它们通常受限于IO操作的速度。使用异步IO、多线程或多进程等技术可以提高IO密集型进程的性能。
示例:Web服务器、数据库服务器、文件上传下载服务等需要频繁IO操作的应用程序。
到此,我们可以给平均负载重新定义,它是指系统中 IO密集型进程和 CPU密集型进程的平均数。这样是不是对平均负载有更好对理解。
而 CPU作为中央处理单元,它是执行系统中各种进程的硬件。 假如每个 CPU上刚好有且只有一个进程在运行,是不是意味着不用切换 CPU,每个进程享受着 CPU 1对1的服务。
因此,如果平均负载等于 CPU个数,就刚好满足了这种 1对1服务,所以,平均负载最理想对情况就是等于 CPU个数。
有了这个前提,可以得出:在单 CPU服务器上 load averages 1 1 1 是最理想的平均负载,同理,在 N个 CPU的服务器上 load averages N N N 是最理想的平均负载。
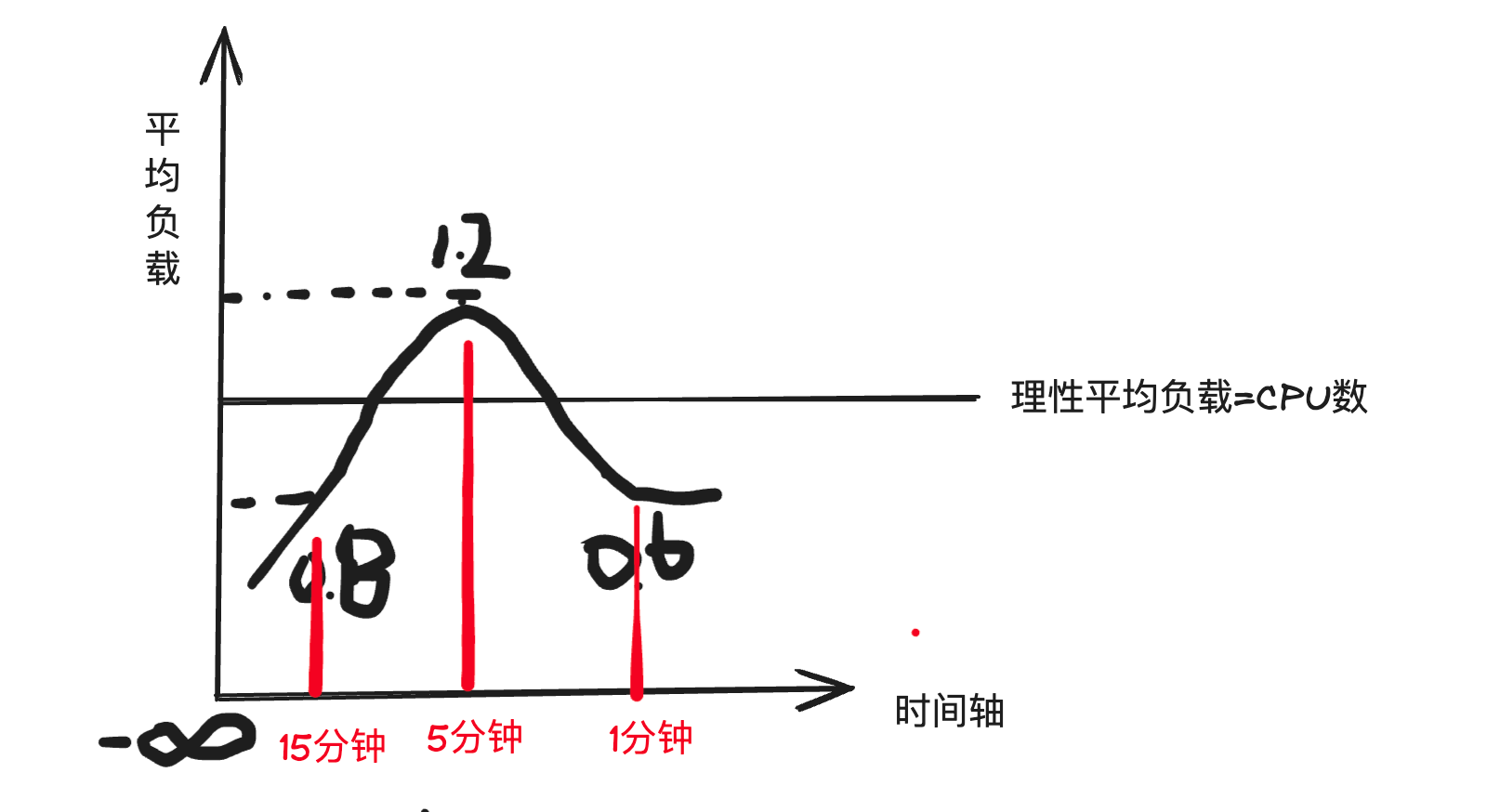
如果 平均负载对3个数字不等于 CPU个数,就代表负载不正常吗? 下面我们分析一个案例:单 CPU服务器 load averages 0.6 1.2 0.8。
1分钟平均负载为0.6, 小于1, 属于低负载,5分钟平均负载为1.2,大于1,系统过载,15分钟平均负载为0.8, 也是低负载。平均负载对整体走势是: 从 15分钟的0.8 升高到 5分钟的 1.2, 因此系统服务在升高,但又从 5分钟的1.2 降到 1分钟的0.6,
说明服务器的负载在降低,最后正常,所以对于 load averages,我们应该按照整个发展趋势来分析,这样才能更好的分析系统的负载变化。趋势可以参考下面对手绘图:
那么,生产环境,平均负载多少是合理的?
业内经验值:小于 CPU总数的 70% 是正常的,超过 70% 就需特别注意。但这个值并不是绝对的,需要根据具体业务具体分析。
最后,平均负载高,CPU就一定高吗?
在讲解进程时提到进程有 CPU密集型和 IO密集型,而 IO密集型对 CPU的影响不大,所以,平均负载高,CPU不一定高。
因此,在生产排查时,如果发现负载高,CPU使用率高,那任务是 CPU密集型概率比较大;如果发现负载高,CPU使用率不是很高,那任务是 IO密集型概率比较大。
CPU飙高排查过程
- 连接到问题服务器;
- 执行 top命令:查找 CPU使用最高的进程PID;
- 执行 jstack > t.log 命令:导出线程堆栈;
- 执行 top -pH pid: 查看进程所有线程的 CPU使用率以及线程Id;
- 执行 printf %x 线程pid:将线程ID转换成16进制ID,并在步骤3中生成的线程堆栈里找到对应的线程;
- 根据堆栈信息,找到对应源码;
总结
- 本文介绍了 4个生产环境常用的系统负载排查指令:top,uptime,htop,w;
- 本文分析了平均负载是什么,以及如何分析负载的3个重要数字;
- 本文分析了平均负载和 CPU的关系: 平均负载理想值等于 CPU数;
- 进程分 CPU密集型和 IO密集型, 对于 CPU密集型进程,负载高,CPU也随着升高; IO密集型进程,负载高,CPU不一定高;
- 文末给出了生产环境 CPU飙高的排查过程;
交流学习
最后,把猿哥的座右铭送给你:投资自己才是最大的财富。 如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
