如何设计一个秒杀系统?
你好,我是猿java。
说起秒杀,大家肯定不陌生,x里的双十一,x东的618,12306抢火车票,直播带货等等,“秒杀”的场景处处可见。那么,作为一个程序员,我们该如何设计一个秒杀系统?如果在面试中遇到这个问题,又该如何作答?今天我们就来聊聊如何设计一个秒杀系统。
什么是秒杀
所谓秒杀,就是在同一个时刻有大量的客户端请求争抢同一个商品并完成交易的过程,瞬时会产生大量的并发读和并发写。
秒杀系统本质上就是一个满足高并发、高性能和高可用的分布式系统。下面给出一张下单交互概要图:
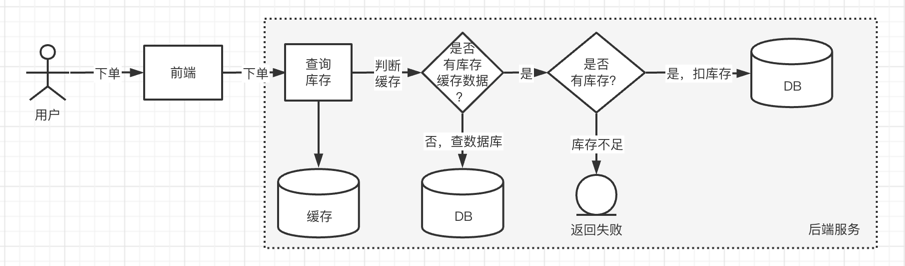
秒杀系统的特点
高性能
秒杀涉及大量的并发读和并发写,因此秒系统必须能支持高并发访问,而且RT(响应时间)需要在一定的范围内,通常是200ms
一致性
秒杀系统中通常会使用缓存,如何保证缓存和数据库中库存数据的一致性,保证商品库存的准确性
高可用
秒杀系统会在瞬间收到大量的读写操作,如何能保证服务能稳定的运行,设计系统时是否考虑到系统容灾问题,保证服务的高可用
可扩展性
当服务达到瓶颈时,如何能实现快速扩容
如何设计秒杀系统
从在上述秒杀概要图中,我们可以知道,整个秒杀流程主要包含前端和后端2个核心部分,因此我们就从这2块来分别讲解秒杀系统是如何设计的
前端秒杀设计
服务高可用
前端是秒杀的入口,用户首先是到前端界面进行商品浏览,然后加购自己想要的商品进行下单付款操作。 所以,前端服务一定要保证高可用,要不然秒杀的入口都没有了,谈何秒杀。
页面静态化
前端数据源动静分离,静态的数据可以放到CDN,前端从CDN获取,动态的数据放到服务器。 静态数据,比如商品的详情信息,图片等;动态数据,商品的数量,价格等。
比如:可以通过Url地址作为key来存储静态数据
控制对服务器请求的频率
控制对服务器请求频率能在一定程度上缓解服务器的压力,限频的方式有很多, 比如 秒杀按钮点击后置灰一定的时长后才能再次点击,
前端 答题正确后才向服务器发起请求,前端将请求加入队列进行排队,当有多个秒杀活动时,可以分时段进行,这些方式都是无损的。
控制对服务器请求参数的大小
因为秒杀期间,瞬时会有大量的请求涌向服务器,所以前端和服务器的数据交互要尽量的少,减少网络传输以及编解码的开销
限流,降级
当下游服务器达到瓶颈时,可以采用前端限流方式,降低对服务器的TPS和QPS。但是当客户端比较分散时,限流阈值的设置是一个比较大的挑战:阈值设的太小,会导致服务端没有达到瓶颈时客户端已经被限制;设的太大,则起不到限制的作用。
后端秒杀设计
服务高可用
后端是处理请求的核心服务,所以必须做好高可用部署,容灾设计(异地多活)
降级,限流,拒绝服务
降级,就是当系统的容量达到一定程度时,限制或者关闭系统的某些非核心功能,从而把有限的资源保留给更核心的业务。所以降级一般需要前后端配合执行,可以通过开关系统来实现。比如: 当QPS达到一个阈值时,可是设置开关,将原来分页查50条数据,变成查10条,减少一次交互的数据量。
限流,就是当系统容量达到瓶颈时,通过限制一部分流量来保护系统,限流可以是接口级别,服务器级别,iP级别等等,此处的限流是有损操作,限流的阈值一般可以根据压测结果来设置
直接拒绝服务,如果限流还不能解决问题,那就直接拒绝服务以求自保,这也是最差的一种兜底情况。
独立部署秒杀服务
秒杀系统和普通的售卖有一定的差异点,秒杀一般是持续时间短,并发量高,所以为了不影响正常的售卖,可以单独部署一套秒杀服务,在物理级别进行隔离,也适合服务端灵活伸缩容以及做一些特殊的个性化处理。
有条件的团队可以实施。
流量削峰
当服务流量过大时,可以将请求存入MQ消息中间件进行削峰处理,客户端可以采用轮询的方式向服务器获取结果(服务器会受到很多结果查询的请求),或者服务主动push结果给客户端(服务需要保留很多和客户端的长链接),2种方式各有优劣,一般生产上轮询查询结果用的比较多。
热点数据探测
很多时候,一个商品不属于秒杀,但是很多用户购买,可能会成为热点数据,请求量不亚于秒杀,所以网关需要有热点数据探测的功能,实现的方式有很多,比如:统计客户端的请求数
增加缓存
秒杀一般遵从读多写少的28法则,所以可以在服务端增加缓存应对高并发读。缓存可以设置2层,第一层是本地缓存,可以使用Google guava的缓存框架,失效时间一般可以秒级别,本地缓存是属于jvm级别的,每次失效后可以从redis缓存中加载,redis缓存要特别注意缓存失效,缓存击穿,缓存雪崩的问题。
缓存击穿:缓存中不存在,数据库存在,这样就会导致请求直接到达数据库,当请求量比较大时,可能直接把数据库打垮。解决方法:
- 可以考虑缓存永远不过期
- 同步返回null,异步加锁查询数据库,更新缓存
缓存穿透:请求的数据在缓存和数据库中都不存在,解决办法:
- 业务层进行合法校验,拦截大部分不合法的请求
- 使用布隆过滤器,针对一个或者多个维度,把可能存在的数据值hash到bitmap中,bitmap中不存在则该数据一定不存在,bitmap中存该数据可能存在
- 对空的结果进行缓存,设置得较短过期时间,当有数据库变更时,必须同时刷新缓存,否则会导致不一致的问题存在
缓存雪崩:指缓存在同一时刻失效,请求都到数据库上,解决的办法:
- 可以考虑缓存永远不过期
- 失效时间尽量随机,避免同时过期
- 多级缓存,数据缓存到A和B,A设置过期时间,B不设置过期时间,如果A为空的时候去读B,同时异步去更新缓存,需要同时更新两个缓存
如何保证不超卖
秒杀一般都是优惠售卖,所以库存不要超卖是前提,一般来说,防止超卖需要前后端配合
库存扣减方式
下单减库存
买家下单后,扣减商品总库存。下单减库存是最简单也是控制最精确的一种,下单时直接通过数据库的事务机制控制商品库存,一定不会出现超卖的情况。出现的问题: 恶意刷单,某些人下单后占用库存不付款。
付款减库存
买家付款之后,扣减商品总库存。这种方式产生的问题是,库存超卖。
预扣库存
买家下单后,预扣库存,在一定的时间内未付款,库存将会自动释放。在买家付款前,需再次校验库存是否保留,如果没有保留,则再次尝试预扣;如果库存不足则不允许继续付款;如果预扣成功,则完成付款并实际地减去库存。这种方式在生产上用的比较多。
服务端库存处理
将库存操作的逻辑放到lua脚本中,通过redis的单线程特性,保证Lua脚本执行不会被打断,从而保证库存操作的原子性
实际经验
分享下自己做社区电商的秒杀活动时库存系统的架构设计,
业务背景:订单日均3000万,TPS1万,QPS10万
前端用到了上述的各种技术;
后端服务器部署 采用读写分离的方式, 库存计算采用了Lua脚本来保证原子性,主库采用Redis cluster,写入redis成功后将数据转发到MQ,最终异步写入Mysql数据库,实现数据的最终一致性,另外增加了对账系统,校准redis和mysql数据的差异性。
面试中如何回答
- 先分析整个流程,然后再按前端和后端两部分去分析
- 前端用到什么技术,目的是什么,会出现什么问题,如何解决
- 后端是侧重点,可从业务架构,技术架构,分布式锁,缓存,数据一致性,容灾来分析
- 最后,做个总结
总结
下面给出一张秒杀系统常用的架构图,百种业务百种架构,一个秒杀系统看似简单,其实包含了很多架构的思想,从前端到后端,怎么全局把控,对于各个服务怎么去做高可用,高性能,可扩展保证。如何设计缓存,如何保证缓存和数据库的数据一致性,服务达到瓶颈时,如何做服务降级,限流。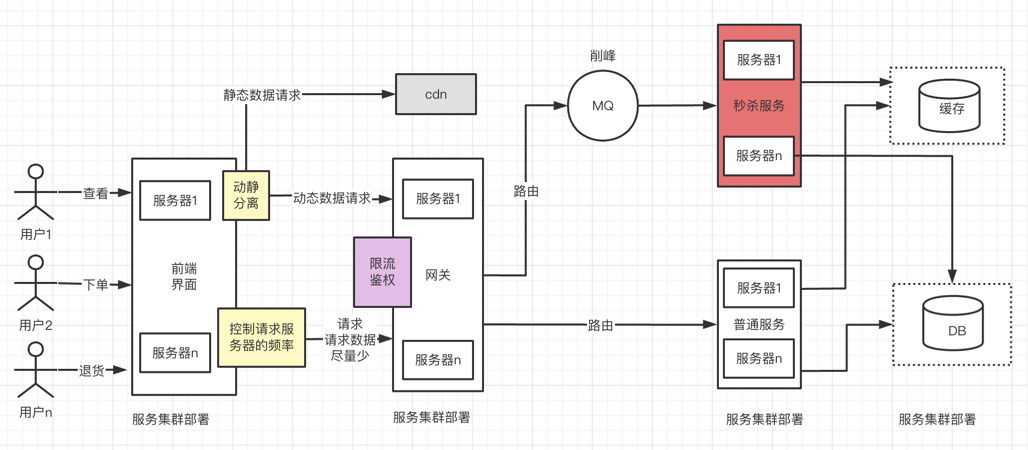
一般我们遵从几个原则:
- 前后端交互的数据尽量少
- 前端尽量控制对后端的无效请求
- 服务之间的依赖尽量少
- 请求路径尽量短
- 服务或者中间件不要有单点,要有容灾
学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
