
深度剖析:线程池运行原理及常见面试题,看完这篇文章彻底懂了!
你好,我是猿java。
今天我们开门见山,直奔主题:线程池。
申明:本文基于 jdk-11.0.15
为什么有线程还需要线程池
关于 Java线程,有兴趣可以参考小编过往的文章:深度剖析:Java线程运行机制,程序员必看的知识点!
我们先看下线程的几个缺陷:
- Java的线程最终是由操作系统创建的,因此线程的创建,调度都受限于操作系统的处理能力;
- 线程在 Java中是一种宝贵的资源,如果程序创建线程时控制不当,可能导致资源耗尽的风险;
- 互联网的快速发张,很多业务场景会涉及到多线程;
鉴于上面的
内容大纲: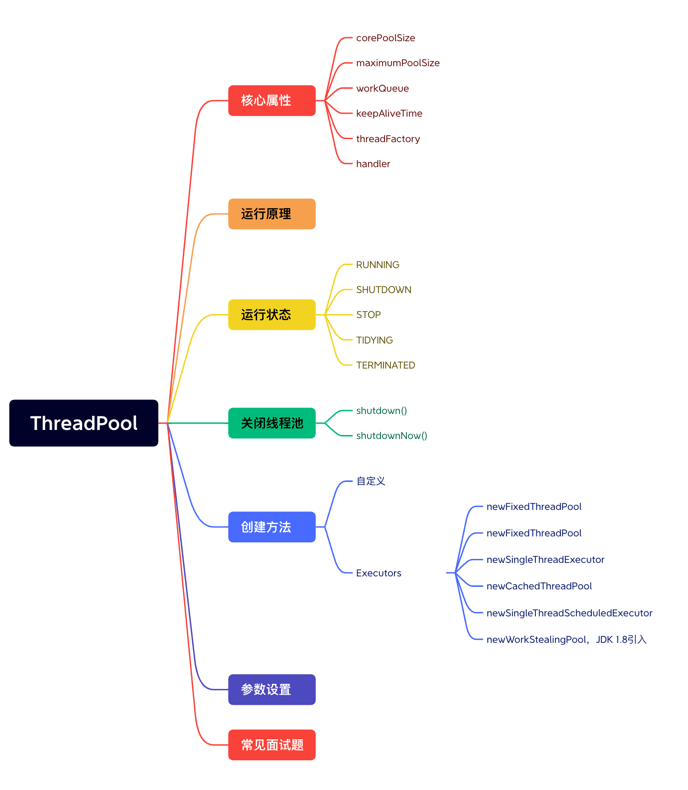
线程池是什么
线程池(Thread Pool)是 JDK 1.5版本开始引入,由大牛 Doug Lea实现,本文的线程池是指J.U.C提供的 java.util.concurrent.ThreadPoolExecutor 类。 它是一种基于池化思想管理线程的工具,更直白的说,线程池就是用来帮助程序员更优的管理线程的工具。
线程池核心属性
下面给出一张创建线程池最底层构造器源码截图(其他方式创建线程池最终都是调用该构造器):
通过 ThreadPoolExecutor源码截图我们可以得出线程池中几个核心的概念:corePoolSize、maximumPoolSize、workQueue、keepAliveTime、threadFactory、handler。
理解了这几个核心概念,线程池基本掌握了50%,下面分别对每个属性进行讲解。
corePoolSize
核心线程数,当提交新任务,如果线程池中的线程数量小于 corePoolSize,即便其它线程处于空闲状态,线程池也会创建一个新线程来处理该任务;
maximumPoolSize
最大线程数,线程池中允许创建的最大线程数阈值。当新任务被提交时:
- 如果线程池中的线程数 countWorker大于 corePoolSize并且小于 maximumPoolSize,任务会被放入队列;
- 如果线程池中的线程数 countWorker大于 maximumPoolSize,假如任务能够放入堵塞队列则放入,否则执行拒绝策略;
workQueue
工作队列,它是 BlockingQueue 堵塞类型,用来传输和保存由 execute()方法提交的 Runnable任务,当线程池中的线程大于等于
corePoolSize 而小于
maximumPoolSize时,任务会被优先放入队列,任务放入队列有 3种策略:
- 直接处理:当 workQueue为
SynchronousQueue(同步队列),则新任务会立即被交给线程池中已有的线程进行处理,如果无法立即获取可用线程,则认为任务放入队列失败,需要重新生成一个线程来处理该任务(如果此时线程数大于
maximumPoolSize,任务被拒绝),为了避免任务被拒绝,一般会把 maximumPoolSize设置成无限大,带来的问题是线程数疯长,有资源耗尽的风险,不过该策略可以避免死锁。 - 无界队列:当 workQueue为无界队列,任务会被放入队列中,等待空闲的线程来处理。如果任务之间是相互独立的,适合使用这种队列,但是当线程处理的速度小于新任务放入的速度,队列会无线封装,依然存在资源耗尽的风险。
- 有界队列:当 workQueue为有界队列,可以规避无界队列资源耗尽的风险,但是这个边界该设置多大比较难把控,如果设置大队列小线程池,虽然可以降低
CPU使用率和线程切换的开销,但是可能导致低吞吐量。
keepAliveTime
保留存活时间,当线程数大于 corePoolSize时,假如线程池无需处理任务,超出 corePoolSize的空闲线程会保留 keepAliveTime时长后被
terminated,如果设置了 allowCoreThreadTimeOut(true),核心线程也会保留 keepAliveTime时长后会被
terminated,keepAliveTime的值可以通过
setKeepAliveTime(long, TimeUnit)方法动态设置;
threadFactory
线程工厂,线程池中的所有线程都是通过 threadFactory进行创建;使用线程工厂可以避免 new Thread()这种硬码创建新线程,我们可以在
threadFactory中使用特殊的线程子类、优先级等功能。
handler
拒绝策略,当 Executor关闭时,以及 Executor对最大线程和工作队列容量都使用有限的界限,并且已经饱和时,在方法 execute(Runnable)
中提交的新任务将被拒绝。线程池提供了 4种拒绝策略:
- AbortPolicy:默认的拒绝策略。直接丢弃任务并抛出 RejectedExecutionException这样一个运行时错误;
- CallerRunsPolicy:任务会被转交给调用 execute()方法的线程处理;
- DiscardPolicy:直接丢弃了无法执行的任务;
- DiscardOldestPolicy:如果线程池没有被关闭,则丢弃工作队列头部的任务(最早放入的任务),然后重试执行(可能再次失败,导致重复此操作);
在实际生产中,我们需要根据具体的业务来自定义拒绝策略:
比如:对于一些不能丢失的数据,可以写数据库、写log或者放入MQ中,当线程池恢复处理能力时,再取出数据进行处理。
比如:在数据库中数据有软状态,可以直接丢弃,当线程池恢复处理能力时,再从数据库中获取数据进行处理。
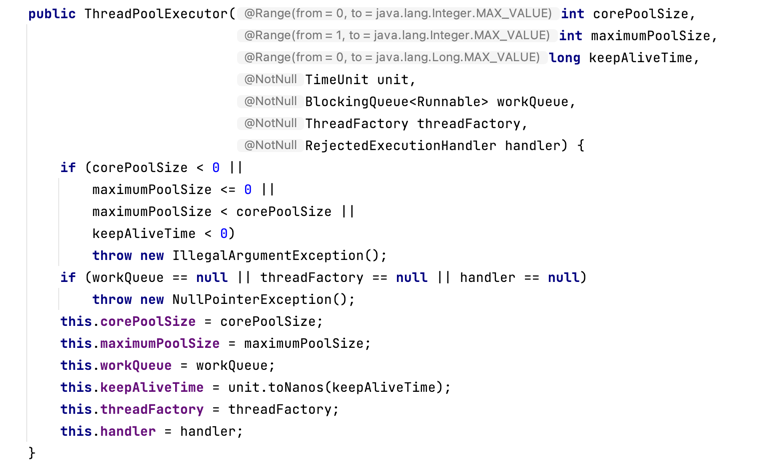
线程池的运行状态
线程池的运行状态主要有 5种:
- RUNNING:接受新任务并处理排队任务;
- SHUTDOWN:不接受新任务,但处理排队任务;
- STOP:不接受新任务,不处理排队任务,并中断正在进行的任务;
- TIDYING:所有任务都已终止,workerCount 为零,转换到状态 TIDYING的线程将运行 terminate()钩子方法;
- TERMINATED:当 terminate()完成,在 awaitTermination()中等待的线程将达到 TERMINATED状态;
5种运行状态的转换关系如下图:
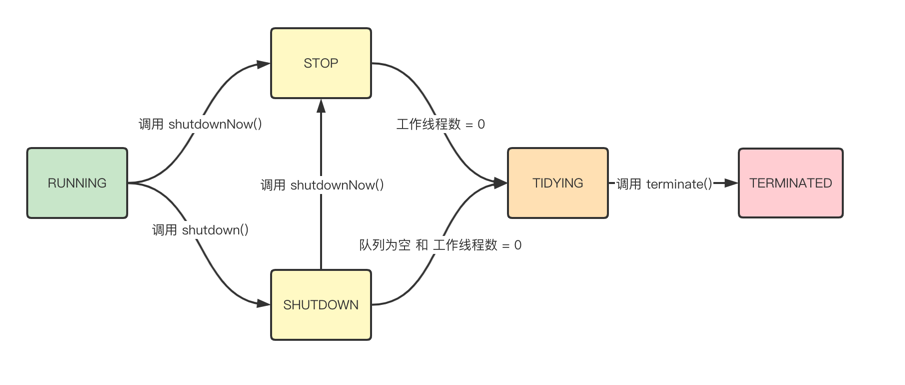
线程池运行状态是通过 ctl变量进行存储的,ctl包装了 workerCount 和 runState两个字段,共 32bit,源码如下:
1 | public class ThreadPoolExecutor extends AbstractExecutorService { |
workerCount:指的是线程池中的工作线程数;
runState:指的是线程池的运行状态,包含 RUNNING、SHUTDOWN、STOP、TIDYING、TERMINATED 5种;
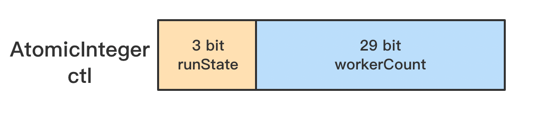
ctl 结构如下图:
线程池工作机制
下面整理了一张线程池工作的核心流程图:
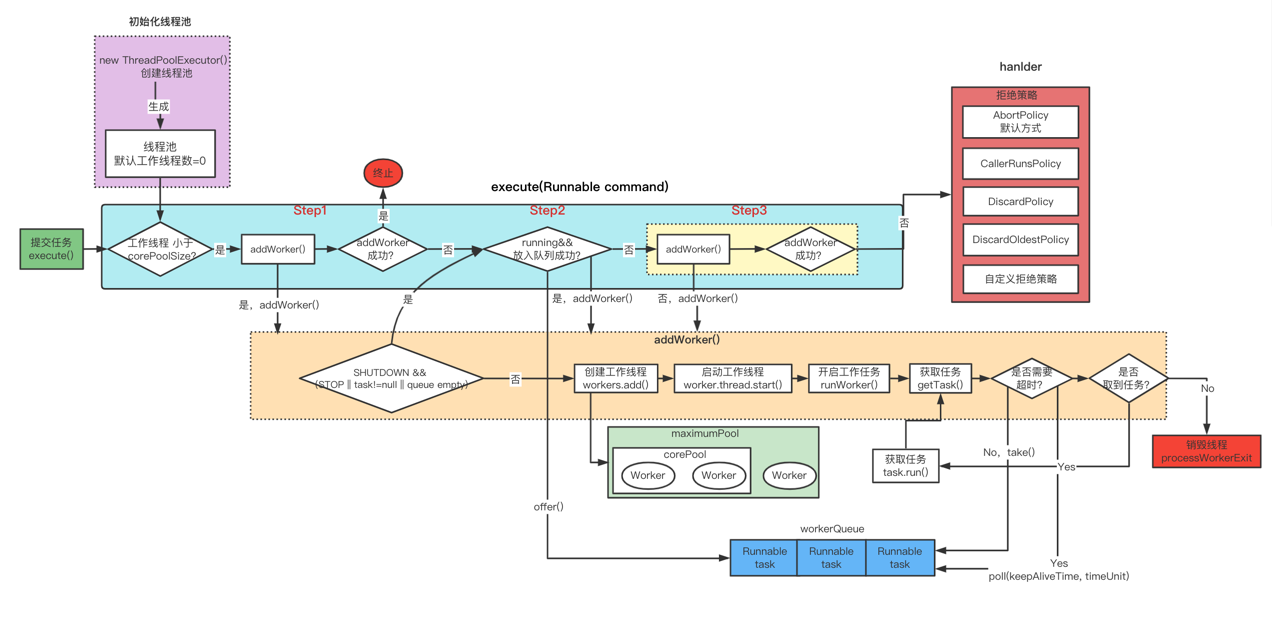
线程池源码分析
execute()方法
1 | public class ThreadPoolExecutor extends AbstractExecutorService { |
execute(Runnable command) 方法总结:
- 如果 workerCount < corePoolSize,则尝试创建并启动一个新线程来执行新提交的任务;
- 如果 workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添 加到该阻塞队列中;
- 如果 corePoolSize <= workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则尝试创建并启动一个新线程来执行新提交的任务;
- 如果 workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的
AbortPolicy策略是直接抛异常;
addWorker()方法
1 | public class ThreadPoolExecutor extends AbstractExecutorService { |
addWorker() 方法总结:
- addWorker()方法的主要作用是在线程池中创建一个新的线程并执行任务;
- firstTask参数用于指定新增的线程执行的第一个任务,
- core参数用来限制创建新线程,是以 corePoolSize还是以 maximumPoolSize作为线程数最大阈值。
- 需要获取 mainLock可重入锁成功才能将 worker加入 HashSet中
- worker添加成功后,调用线程的t.start() 启动线程执行任务;
Worker类分析
1 | private final class Worker extends AbstractQueuedSynchronizer implements Runnable { |
Worker类总结:
- Worker类实现了 Runnable接口,因此是一个线程类。
- Worker类继承了AQS,使用了 AQS实现独占锁的功能。
- 为什么不使用 ReentrantLock可重入锁来实现?
从源码的 tryAcquire()方法可以看出它是不允许重入的,而ReentrantLock是允许可重入的:
- lock方法一旦获取独占锁,表示当前线程正在执行任务中;
- 如果正在执行任务,则不应该中断线程;
- 如果该线程现在不是独占锁的状态,也就是空闲状态,说明它没有处理任务,这时可以对该线程进行中断;
- 线程池中执行shutdown方法或tryTerminate方法时会调用interruptIdleWorkers方法来中断空闲线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态;
- 之所以设置为不可重入的,是因为在任务调用setCorePoolSize这类线程池控制的方法时,不会中断正在运行的线程所以,Worker继承自AQS,用于判断线程是否空闲以及是否处于被中断。
runWorker()
1 | private final class Worker extends AbstractQueuedSynchronizer implements Runnable { |
runWorker()方法总结:
- while 死循环通过getTask()方法从阻塞队列中获取任务,当getTask()为null时跳出 while()循环;
- 正常进入 while死循,先加锁,然后进入任务处理逻辑;
- 如果线程池正在停止,则中断当前线程,调用 processWorkerExit()方法,runWorker()结束;
- 调用 task.run() 执行任务;
- while 循环不论何种原因跳出,最终都需要执行 processWorkerExit()方法;
- runWorker()方法执行成功,意味着 Worker中的 run()方法执行成功,则释放锁,销毁当前线程;
getTask()方法
1 | public class ThreadPoolExecutor extends AbstractExecutorService { |
getTask()方法总结:
- 判断线程池的 runState决定是否能返回任务;
- 判断是否需要对超出 corePoolSize的线程最超时推出操作;
- 根据 timed来判断 采用什么方式从阻塞队列中获取任务;
processWorkerExit()方法
1 | public class ThreadPoolExecutor extends AbstractExecutorService { |
到此,线程池的核心方法已经分析完毕,那么,我们需要如何创建线程池呢?
线程池创建方式
手动创建
参数按需设置,比如下面代码就是自己创建的一个线程池:
1 | ThreadPoolExecutor executor=new ThreadPoolExecutor(2, |
使用 Executors提供的方法
newFixedThreadPool
固定线程数的线程池,corePoolSize = maximumPoolSize,keepAliveTime = 0,工作队列为无界堵塞队列 LinkedBlockingQueue。
- 优点:线程数是固定的,不会无限增长。
- 缺点:线程数是固定的,无法动态调整;工作队列是无界的,如果任务堆积过多可能导致内存溢出;不支持自定义拒绝策略
newSingleThreadExecutor
只有一个线程的线程池,corePoolSize = maximumPoolSize = 1,keepAliveTime = 0,工作队列为无界堵塞队列 LinkedBlockingQueue。
- 优点:可以顺序执行任务
- 缺点:线程数为1,不支持并发,无法动态调整;工作队列是无界的,如果任务堆积过多可能导致内存溢出;不支持自定义拒绝策略
newCachedThreadPool
按需要创建新线程的线程池,核心线程数为0,最大线程数为 Integer.MAX_VALUE,keepAliveTime = 60s,工作队列使用同步SynchronousQueue。
- 优点:可以无线添加新的线程,当需求降低时会自动回收空闲线程。适用于执行很多的短期异步任务,或者是负载较轻的服务器。
- 缺点:不支持自定义拒绝策略
newScheduledThreadPool
创建一个以延迟或定时的方式来执行任务的线程池,堵塞队列为 DelayedWorkQueue。
- 优点:适用于需要多个后台线程执行周期任务
- 缺点:任务是单线程方式执行,一旦一个任务失败其他任务也受影响;不支持自定义拒绝策略
newWorkStealingPool
窃取(抢占式操作)线程池,JDK 1.8 新增,底层使用 ForkJoinPool 实现,1个任务拆分成多个”小任务”,”小任务”被分发到多个线程上执行,”小任务” 都执行完成后,再将结果合并。每一个线程都有一个自己的队列,当线程发现自己的队列没有任务了,就会到其它线程的队列里获取任务执行,这个过程理解为”窃取”。
和上面 4种线程池有很明显的区别,前 4种线程池都有核心线程数、最大线程数等等,而这就使用了一个并发线程数解决问题,任务的执行是无序的,哪个线程抢到任务。
- 优点:每个线程有自己的队列,可以减少队列的争用,适合并发量大的任务
- 缺点:不会保证任务的顺序执行,不支持自定义拒绝策略
线程池终止方式
终止线程池主要有两种方式:
- shutdown():不接受新任务,但是在关闭前会将之前提交的任务处理完毕。
- shutdownNow():直接关闭线程池,通过 Thread.interrupt()方法终止所有线程,不会等待之前提交的任务执行完毕,但是会返回队列中未处理的任务。
如何配置线程池
线程池参数的配置,会依据服务器的工作类型来设置,参考意见如下:
计算密集型,设置 线程数 = CPU数 + 1;
I/O密集型,线程数 = CPU数 * 2;
但是在实际开发中,服务器很难完全区分是哪一种类型,因此一个比较合理的设置是:
线程数 = CPU数 * CPU利用率 * (任务等待时间 / 任务计算时间 + 1)
比如,程序部署在 4核的服务器上用于任务计算,假设任务计算时长是 100ms,等待 I/O操作为 400ms,则线程数约为:4 * 1 * (1 + 400 / 100) = 20个
不过,上面的都是参考值,在实际生产中的做法是:经过压测得出最佳线程数,并且把 corePoolSize 和 maximumPoolSize
设计成可配置化参数,一旦需要调整大小,可以直接通过配置中心来完成,以免重新发布代码。
常见面试题
注意:在面试中回答线程池的问题,一定要先说明 jdk版本,因为不同的版本实现可能有差异(jdk修复bug或者性能优化导致的)。有了上面对线程池原理的分析,下面的面试题可以很容易的回答。
1.为什么有线程还需要线程池呢?
线程在正常执行或者异常中断时会被销毁,如果频繁的创建很多线程,不仅会消耗系统资源,还会降低系统的稳定性,一不小心把系统搞崩了。
使用线程池可以带来以下几个好处:
- 线程池内部的线程数是可控的;
- 可以灵活的设置参数;
- 线程池内会保留部分线程,当提交新的任务可以直接运行;
- 方便内部线程资源的管理,调优和监控;
2.能讲下线程池中几个核心属性吗?
参考上述 核心属性 章节
3.能讲下线程池的运行原理吗?
参考上述 运行原理 章节
4.线程池中的核心线程会被销毁吗?
默认情况下不会,但是如果设置了 allowCoreThreadTimeOut(true),核心线程也会保留 keepAliveTime时长后会被 terminated。
5.能讲下线程池的运行状态吗?他们之间是如何转换的?
参考上述 线程池的运行 章节
6.能聊聊线程池的拒绝策略吗?
参考上述 拒绝策略 章节
7.能讲讲 ctl的实现机制吗?
ctl将 runState 和 workerCount 封装成了一个原子 AtomicInteger操作。因为 runState 和 workerCount 是线程池正常运行的2个最重要属性。
因此无论是查询还是修改,我们必须保证对这2个属性的操作是属于“同一时刻”的,也就是原子操作,否则就会出现错乱的情况。如果我们使用2个变量来分别存储,要保证原子性则需要额外进行加锁操作,这显然会带来额外的开销,而将这2个变量封装成1个
AtomicInteger 则不会带来额外的加锁开销,而且只需使用简单的位操作就能分别得到 runState 和 workerCount。
由于这个设计,workerCount 的上限 CAPACITY = (1 << 29) - 1,对应的二进制原码为:0001 1111 1111 1111 1111 1111 1111
1111(29个1)。
通过 ctl得到 runState:runState = ctl & CAPACITY。( 按位取反),于是”~CAPACITY”的值为:1110 0000 0000 0000 0000 0000 0000
0000,只有高3位为1,与 ctl 进行 & 操作,结果为 ctl
高3位的值,也就是 runState。
通过 ctl得到 workerCount:workerCount = c & CAPACITY(位操作)。
8.Executors提供了哪些创建线程池的方法?
参考上述 线程池创建方法 章节
9.线程池中的核心线程数和最大线程数该如何设置呢?
10.如何终止线程池?
参考上述 终止线程池 章节
11.为什么线程池中要使用堵塞队列?
- 主要原因:线程从阻塞队列取任务时,如果阻塞队列不为空则立即返回,如果为空,则线程会被阻塞,一直等待,直到队列中有新的任务,这样就充分的利用了阻塞队列
堵塞和通知线程的功能。如果采用非堵塞队列,则需要写额外的机制来实现通知线程获取任务。 - 次要原因:当核心线程处理不过来,可以通过堵塞队列进行任务堆积
12. 非核心线程能成为核心线程吗?
核心线程和非核心线程是理解上的区分,线程池内部并不区分核心线程和非核心线程的,会根据池的工作线程数 countWorker和 corePoolSize 进行调整,
- 当 countWorker <= corePoolSize,则 countWorker这些线程被理解成核心线程;
- 当 corePoolSize < countWorker < maximumPoolSize,则 countWorker - corePoolSize 这部分线程被理解成非核心线程;
13. 线程池中的线程在什么时候创建?
默认情况下,即使是核心线程也只能在新任务到达时才创建和启动。但是可以使用 prestartCoreThread 或 prestartAllCoreThreads 方法来提前启动核心线程,即创建线程池的时候就会创建对应数量的线程。
14. 有界队列和无解队列有什么风险?
- 有界队列,当线程池的队列满了后,被拒绝的任务如何处理;
- 无界队列,当任务的提交速度大于线程池的处理速度,可能会导致内存溢出;
1.5 为什么不推荐使用Executors包装的线程池?
参考上述 线程池创建方式 章节
总结
到此,我们对线程池进行了全面的分析,也列举了面试中常见的问题,对于线程池的学习,个人极力推荐优先阅读源码,毕竟是原滋原味,然后结合一些优秀的文章,比如本文😁,对照着理解,这样的话就能快速的掌握理论,
但是,光有理论还不行,还应该多参与一些关于线程池的开发工作,也可以多参与一些生产环境线程池的监控和排错任务,加强实战水平,这样才能在工作和面试中游刃有余。
文章总结不易,看到的这里的小伙伴,还请帮忙点赞,关注哦!
学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
